결측치 처리 방법들
데이터에 있는 결측치들을 처리하는 여러가지 방법들이 있다.
- 결측값인 채로 처리: 결측값인 채로 모델링 가능한 모델들이 있다. (예: GBDT모델)
- Zero Imputation: 0으로 대치한다.
- Constant Imputation: 지정한 상수값으로 대치한다. (예: -9999)
- 대표값으로 채우기: 해당 열의 평균값, 중앙값, 최빈값 등을 구해서 대치한다. 하지만 결측값이 랜덤하게 발생하는 경우가 아니라면 적절한 방법은 아니다.
- 단순확률대치법(Single Stochastic Imputation): 관련된 비슷한 데이터 셋에서 랜덤하게 선택한다. (예: Hot-Deck imputation)
- 다른 변수들로부터 모델을 만들어서 결측값 예측: KNN, DNN, Stochastic regression, Extrapolation&Interpolation
- 결측값으로 새로운 특징 만들기: 결측 여부를 0, 1 혹은 행마다 결측값이 있는 변수의 수를 카운팅 한다.
결측치 지정하기: na_values, np.nan
[사용 데이터셋: https://www.kaggle.com/fedesoriano/heart-failure-prediction?select=heart.csv]
데이터 파일을 불러올 때 na_values 파라미터에 결측치로 볼 값들을 지정하면 해당 값들은 결측치로 변환되어 불러진다.
from pandas import read_csv
df=read_csv("./data/heart.csv", na_values=['', 'NA', -1, 9999])
결측치를 지정하는 또 다른 방법은 replace 함수를 사용하여 특정 값을 np.nan으로 치환하는 방법이다.

결측치 확인: isna().sum()
데이터프레임 객체에 .isna()를 하면, 결측치를 True로 반환해 준다. 그 상태에서 뒤에 .sum()을 붙이면 각 feature 별 결측치의 합계를 확인할 수 있다.

결측치 처리: 삭제, 특정값으로 채우기
결측치를 삭제하려면 데이터프레임 객체에 .dropna()를 적용하면 되는데 이때 파라미터 axis=0을 지정하면 행방향으로 결측치가 있는 행이 삭제가 되고, axis=1을 지정하면 열방향으로 결측치가 있는 열이 삭제 된다. 특정값으로 결측치를 대치하려면 결측치가 있는 데이터프레임 객체에 .fillna(채울 값)를 적용하면 된다.

결측치 처리: SimpleImputer - 평균, 중앙값, 최빈값으로 대치
Scikit Learn의 SimpleImputer 함수를 이용해 결측치를 평균, 중앙값, 최빈값으로 대치할 수 있다. 결측치(np.nan)뿐만 아니라 파라미터 missing_values에 대치하고자 하는 값을 지정해서 값을 대치할 수도 있다.

결측치 처리: IterativeImputer - 다변량 대치 방법
다른 모든 특성에서 각 특성을 추정하는 다변량 대치방법이다. Scikit Learn의 IterativeImputer 함수를 이용한다. 해당 함수를 사용하기 위해서는 enable_iterative_imputer의 import가 선행되어야 한다. 라운드 로빈 방식으로 다른 feature들로 결측값이 있는 feature를 모델링 하여 결측값을 대치한다.

결측치 처리: KNNImputer
마찬가지로 Scikit learn의 KNNImputer 함수를 사용한다. 평균, 중앙값, 최빈값으로 대치하는 경우보다 더 정확할 때가 많다. 반면 전체 데이터셋을 메모리에 올려야 해서 메모리가 많이 필요하고 이상치에 민감하다는 단점이 있다. 대치값을 판단할 기준이 되는 이웃의 개수는 n_neighbors 파라미터로 설정할 수 있다.

이상값 처리 방법들: Trim, Winsorizing, DBSCAN
이상값을 처리하는 방법들로는 이상치들을 절단(trim)하는 방법, 이상치들을 이상치의 하한값, 상한값으로 변환하는 조정(winsorizing)의 방법이 있다. 이상값에 대한 정의는 아래와 같이 여러가지가 있기 때문에 분석자가 데이터셋의 상황에 맞게 판단해서 선택해야 한다.
- ESD(Extreme Studentized Deviation): 평균으로부터 3 표준편차 떨어진 값들
- 일반 데이터의 범위를 벗어나는 경우 1: 기하평균-2.5표준편차 < data < 기하평균 + 2.5표준편차
- 일반 데이터의 범위를 벗어나는 경우 2: Q1-1.5*(IQR; Q3-Q1) < data < Q3+1.5*(IQR; Q3-Q1)
- Boxplot을 통해 이상값으로 o 표기되는 경우
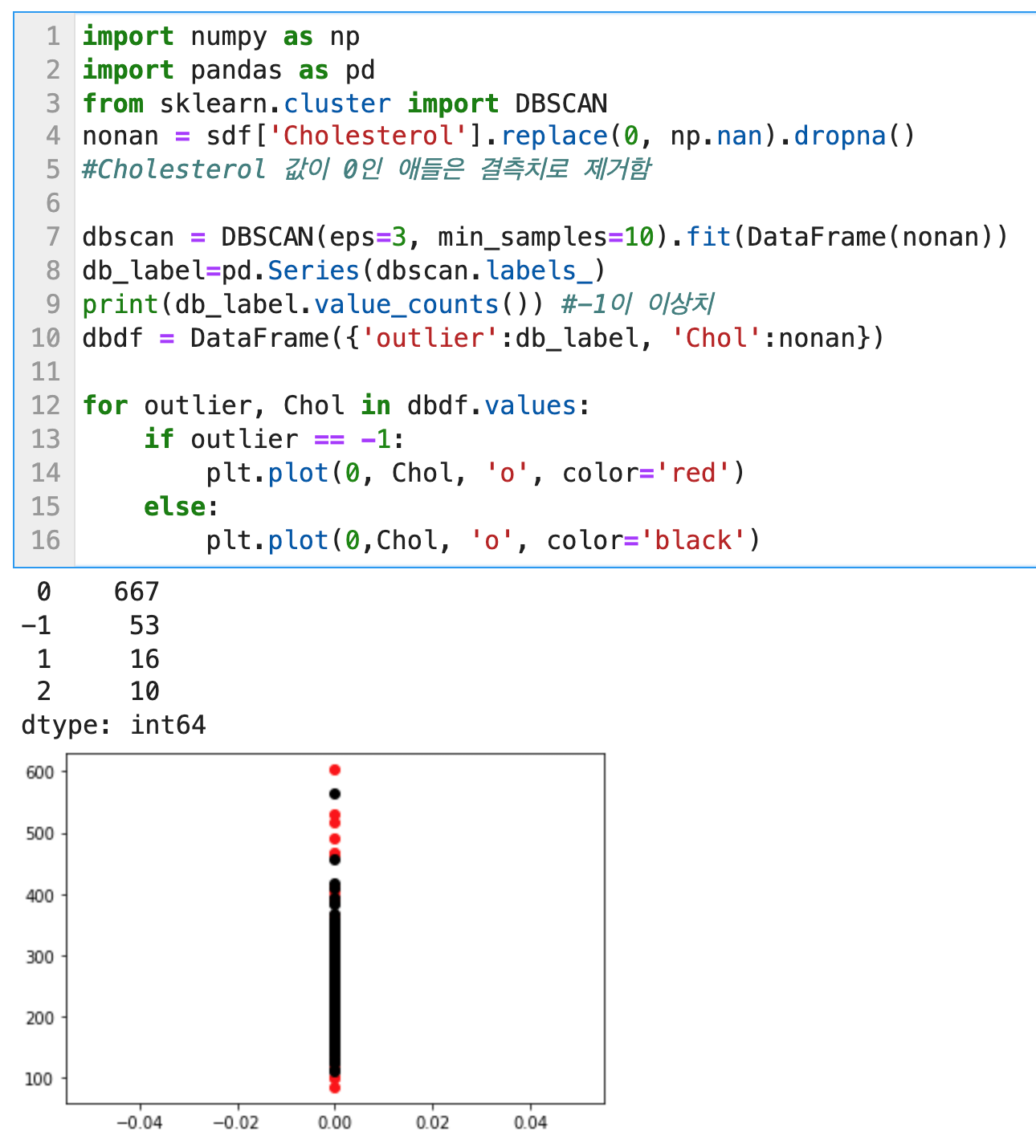
- DBSCAN 클러스터링을 통해 타겟값이 -1이 되는 경우
절단(Trim or Truncation): 경계값 너머의 이상치(outlier)들을 제거
IQR*1.5를 계산하여 데이터의 상한값과 하한값을 찾고 그 너머의 값들을 제거하는 방법이다. 데이터프레임객체에 .quantile(백분위수)를 찾고, IQR을 계산하여 상한값(line_up)과 하한값(line_down)을 찾았다. .quantile(0.25)를 하면 데이터의 25% 지점에 해당하는 1사분위수를 계산할 수 있고, .quantile(0.75)를 하면 데이터의 75% 지점에 해당하는 3사분위를 얻을 수 있다.
데이터프레임객체에 .query()를 활용해서 해당 열에서 하한값보다 작거나 상한값보다 큰 아웃라이어값들의 인덱스값을 out_index 변수에 담았다. 아웃라이어의 인덱스에 해당하는 행은 drop함수를 통해 삭제 했고 그 결과값을 trimmed 객체에 저장했다.
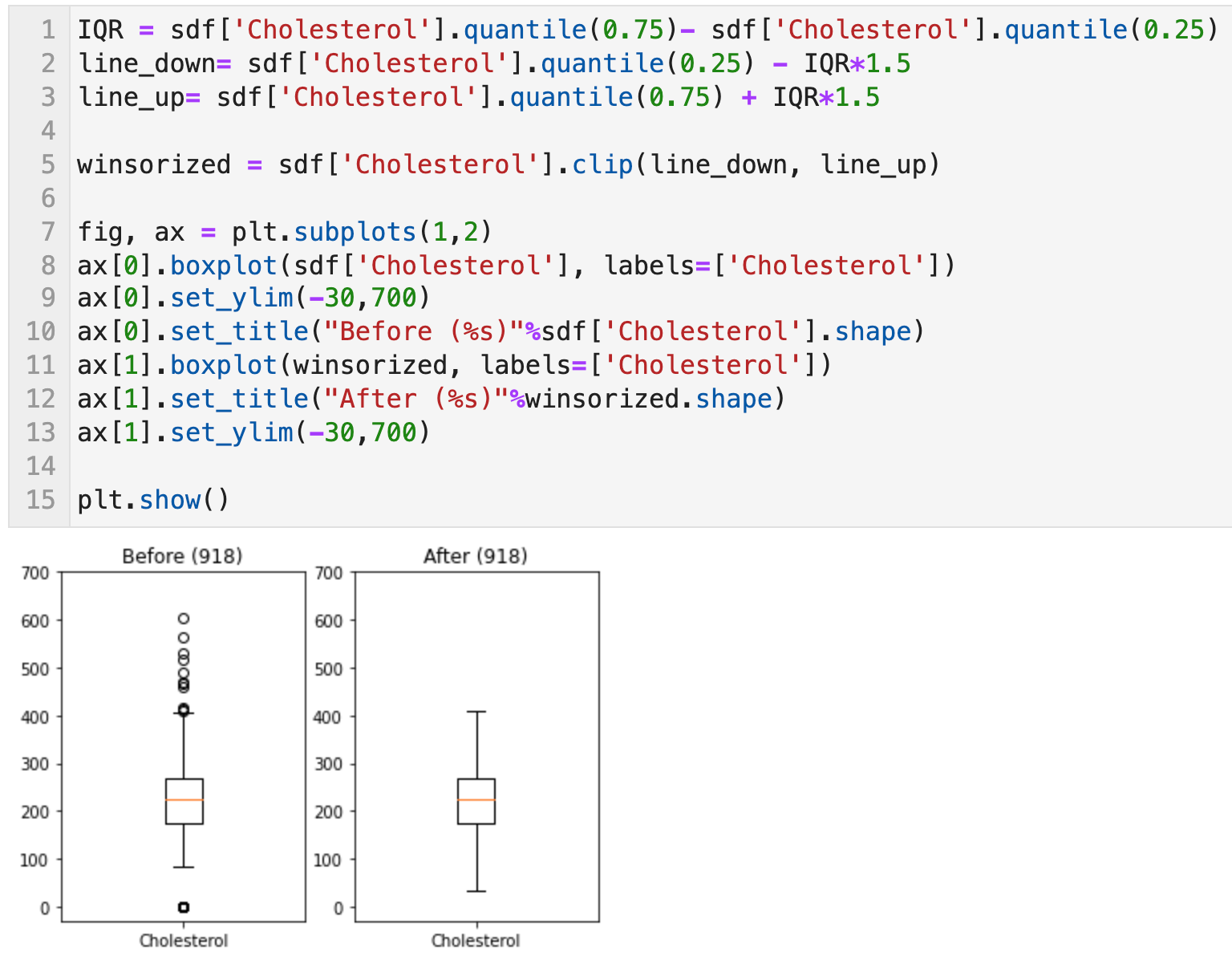
trim전 데이터 수는 918개인데 trim 후 735개의 데이터가 되었고, 박스플롯을 통해 그 전에 있던 이상치들은 사라졌음을 확인할 수 있다.

조정(Winsorizing or clipping): 경계값 너머의 이상치들을 상한값, 하한값으로 치환
조정하려는 데이터 객체에 .clip(하한값, 상한값)이라는 함수를 활용하면 간편하게 조정된 데이터셋을 얻을 수 있다. 이상치의 경계인 상한값과 하한값은 분석가가 데이터셋의 상황에 따라 알맞게 정의할 수 있다. 나는 아래에서 IQR*1.5를 기준으로 한 이상치 경계를 구해 적용했다. (line_down, line_up)
조정 전 데이터 개수는 918개이고, 조정 후 데이터 개수도 918개인데, 이상치가 상한값, 하한값으로 치환되어 조정 후에는 박스플롯에 이상치가 보이지 나타나지 않게 된다.
DBSCAN: -1로 구분되는 이상치들을 제거
밀도기반 클러스터링 기법 중 하나인 DBSCAN을 사용하여 데이터셋을 이상치와 나머지로 클러스터링 할 수 있다. Scikit learn의 DBSCAN 함수를 사용한다.
불균형 클래스 처리 방법들: Oversampling, Undersampling
머신러닝 분류 모델들 중 이진 분류의 경우는 타겟 변수의 경우 0과 1의 값을 가지게 된다. 그런데 현실 세계에서 이 0과 1의 값의 불균형이 매우 심하다. 예를 들어, 백만장자가 된 사람들은 1, 나머지는 0이라고 할 경우 1000명 중 극히 소수의 데이터만 1로 체크가 될 것이다. 이 경우, 적은 수의 클래스의 분포를 제대로 학습하지 못하고 많은 수의 클래스의 분포에 과대적합되어 어떤 데이터가 들어오더라도 Major class로 분류하는 문제가 발생하게 된다. (위의 경우, 1로 분류해야 하는데 0으로 분류하는 오류)
이 때문에 오버샘플링이나 언더샘플링을 통해 불균형 클래스를 처리해야 한다. 대체적으로 Minor class의 데이터 수가 매우 적기 때문에 언더샘플링보다는 오버샘플링을 주로 사용하게 된다.
오버샘플링은 Imbalanced Learn 패키지를 먼저 설치해야 한다.
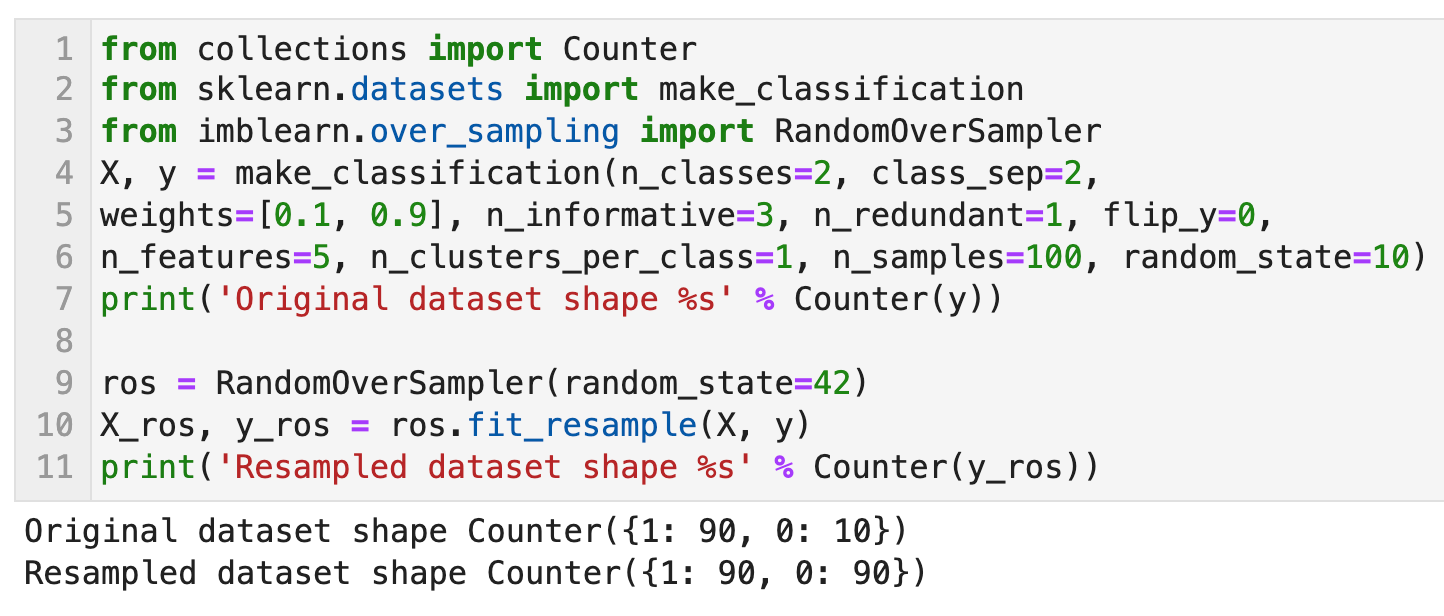
Random Oversampling
기존에 존재하는 Minor class를 단순 복제하여 각 클래스의 비율이 동일하도록 맞춰주는 방법이다. 단순 복제하여 분포는 변화하지 않지만 숫자가 늘어나기 때문에 더 많은 가중치를 받게 된다. 실험적으로 종종 유효할 때가 있지만 똑같은 데이터의 증식이기 때문에 오버피팅의 위험이 있다.
SMOTE (Synthetic Minority Oversampling Technique)
임의의 Minor class 데이터로부터 인근 Minor class 데이터 사이에 새로운 데이터를 생성하는 방법이다. Minor class에 해당하는 데이터 포인트와 근접하는 k개의 이웃을 찾고 그 둘 사이에 새로운 Minor class 데이터 포인트를 생성하는 원리이다.

Borderline-SMOTE
Major class와 Minor class를 구분하는 경계선을 그을 때 서로 인접해 있는 경계선에 있는 Minor class 데이터들에 대해서 SMOTE를 적용하는 방법이다. Minor class 데이터 포인트에 인접한 k개의 데이터들 중 절반 이하가 Minor class 데이터일 경우, 해당 Minor class 데이터 포인트와 k개의 이웃들 사이에 새로운 Minor class 데이터 포인트를 생성한다. 즉, SMOTE를 적용한다.

ADASYN (Adaptive Synthetic Sampling)
Borderline-SMOTE와 마찬가지로, Major class와 Minor class를 구분하는 경계선을 그을 때 서로 인접해 있는 경계선에 있는 Minor class 데이터들에 대해서 SMOTE를 적용하는 방법이다. ADASYN의 경우, 인접한 Major class의 비율에 비례하도록 샘플의 수가 정해지고 SMOTE를 적용한다.

원본 데이터 분포 vs 오버샘플링된 분포
원본 데이터의 분포와 각 오버샘플링 방법들로 만들어진 데이터셋의 분포를 비교해 보았다. 클래스 불균형을 맞추기 위해 oversampling된 피처들의 데이터 포인트 분포는 아래와 같다.

다음에 이어지는 전처리 2탄에서는 변수 변환 (Feature Scaling) 방법을 수치형과 범주형으로 나누어 총정리 해 보고자 한다.
https://lovelydiary.tistory.com/417
ADP) 3-1. 전처리 2탄 (변수 변환; Feature Scaling 총정리 - 수치형/범주형)
변수변환 (Feature Scaling) 변수변환이란, feature의 스케일을 바꾸는 feature 정규화를 의미한다. 입력 feature들의 스케일이 서로 크게 다른 상황에서 유용하다. 어떤 수치형 feature들은 무한히 증가하
lovelydiary.tistory.com
가도와키 다이스케, 사카타 류지, 호사카 게이스케, 히라마쓰 유지, 데이터가 뛰어노는 AI 놀이터, 캐글 (서울: 한빛미디어)
안드레아스 뮐러, 세라 가이도, 파이썬 라이브러리를 활용한 머신러닝 번역개정판 (서울: 한빛미디어, 2019)
앨리스 젱, 아만다 카사리, 피처 엔지니어링 제대로 시작하기 (서울: 에이콘, 2019)
웨스 맥키니, 파이썬 라이브러리를 활용한 데이터 분석 (서울: 한빛미디어, 2016)
Over-Sampling Methods, Imbalanced Learn, https://imbalanced-learn.org/stable/references/over_sampling.html




댓글