의사결정나무(=결정트리, Decision Tree)란?
분류와 회귀 문제에 널리 사용한다. 결정에 다다르기 위해 예/아니오 질문을 이어 나가면서 학습한다. 트리의 노드node는 질문이나 정답을 담은 네모 상자이다. 특히 마지막 노드는 리프leaf라고도 한다. if-then 규칙의 가장 마지막 부분, 혹은 트리의 마지막 가지 부분을 의미한다. 트리 모델에서 잎 노드는 어떤 레코드에 적용할 최종적인 분류 규칙을 의미한다. 엣지edge는 질문의 답과 다음 질문을 연결한다. 맨 위의 노드는 루트노드root node이다.
결정 트리를 학습한다는 것은 정답에 가장 빨리 도달하는 예/아니오 질문 목록을 학습한다는 뜻이다. 머신러닝에서는 이런 질문들을 테스트라고 한다. 트리를 만들 때 알고리즘은 가능한 모든 테스트(질문)에서 타깃값에 대해 가장 많은 정보를 가진 것을 고른다. 테스트를 통해 분기가 일어난 결과값을 볼 때 0과 1로 나는 데이터 개수를 확인할 수 있다. 각 테스트는 하나의 특성에 대해서만 이루어지므로 나누어진 영역은 항상 축에 평행한다. 데이터를 분할 하는 것은 각 분할된 영역(리프)이 한 개의 타깃값(하나의 클래스 혹은 하나의 회귀분석 결과)을 가질 때까지 반복된다. 타깃 하나로만 이뤄진 리프 노드를 순수 노드pure node라고 한다.
파이썬의 Scikit learn 패키지를 활용하면 분류트리와 회귀트리를 손쉽게 구현할 수 있다. 아래에서 분류트리와 회귀트리의 함수 사용방법을 정리해보았다.
Scikit Learn으로 분류트리 구현하기 - DecisionTreeClassifier()
타겟값이 클래스를 갖는 범주형 변수일 때 사용하는 결정트리이다. 분류 예제는 다음과 같다.
sklearn.tree로부터 DecisionTreeClassifier, plot_tree, export_text 함수들을 import한다. 그리고 X, y 별로 훈련용 데이터셋과 테스트용 데이터셋을 나눈다.
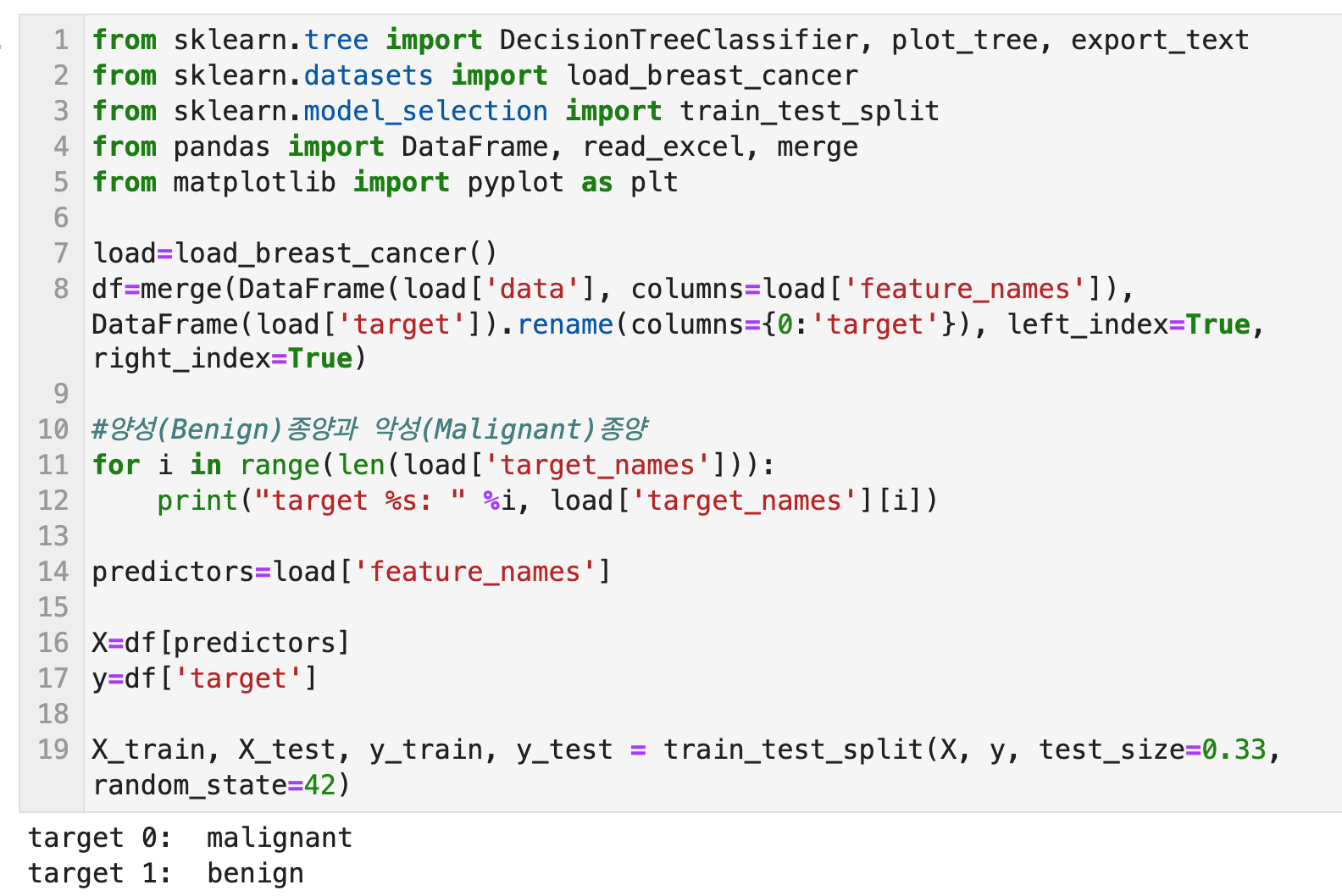
DecisionTreeClassifier()함수로 결정트리를 학습할 방식들을 파라미터로 입력한다. 여기에 들어가는 파라미터들은 아래와 같다. 물론 다 넣을 필요는 없고 학습 결과에 따라서 사용할 파라미터를 선택하고 설정하면 된다.
- criterion: 불순도 척도. 'gini', 'entropy', default='gini'
- splitter: 각 노드의 분할 전략. 최적분할과 최적 랜덤분할. 'best', 'random', default='best'
- max_depth: 트리 깊이의 최대값. 값을 입력하지 않을 경우, 모든 leaf가 pure해질때까지 혹은, 분기된 노드 속 샘플수가 설정한 최소 샘플수(min_samples_split)보다 적게 될때까지 분기한다. 'int값 입력'
- min_samples_split: 분기 할 node 내 샘플의 최소 개수. 최소 개수보다 node 내 샘플 수가 적으면 leaf가 pure하지 않더라도 분기를 멈춘다. float 입력 시, 전체 샘플 개수 대비 float 비율만큼의 개수로 최소 샘플수가 설정된다. 'int 혹은 float값 입력', default=2
- min_samples_leaf: leaf 노드에 있어야 하는 최소 샘플 수. 왼쪽 혹은 오른쪽 branch에 각각 min_samples_leaf만큼 훈련 샘플이 있어야 분기가 된다. 'int 혹은 float값 입력', default=2
- min_weight_fraction_leaf: 모든 샘플의 가중치의 합계의 최소 가중치의 비율, 입력되지 않으면 모든 샘플의 가중치는 동일하다. 'float 입력', default=0.0
- max_features: 최적의 분할을 찾기 위해 고려하는 feature의 개수. 'int or flaot값', 'auto', 'sqrt', 'log2', default=None.
- random_state: 추정기의 무작위성 제어. 'int 입력', default=None
- max_leaf_nodes: 최대 노드 수. default=None
- min_impurity_decrease: 최소 불순도 감소값 이하인 경우에는 분기가 일어나지 않는다. 'float', default=0.0
- class_weight: class별로 가중치를 둔다. 'dict', 'list of dict', 'balanced', default=None, dict의 예시 - {class_label: weight} or [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] instead of [{1:1}, {2:5}, {3:1}, {4:1}].
- ccp_alpha: 최소 비용-복잡성 가지치기에 사용되는 복잡도 매개변수. ccp_alpha보다 작은 비용-복잡도를 가진 하위 트리 중에 비용-복잡도가 가장 큰 하위 트리가 선택된다.
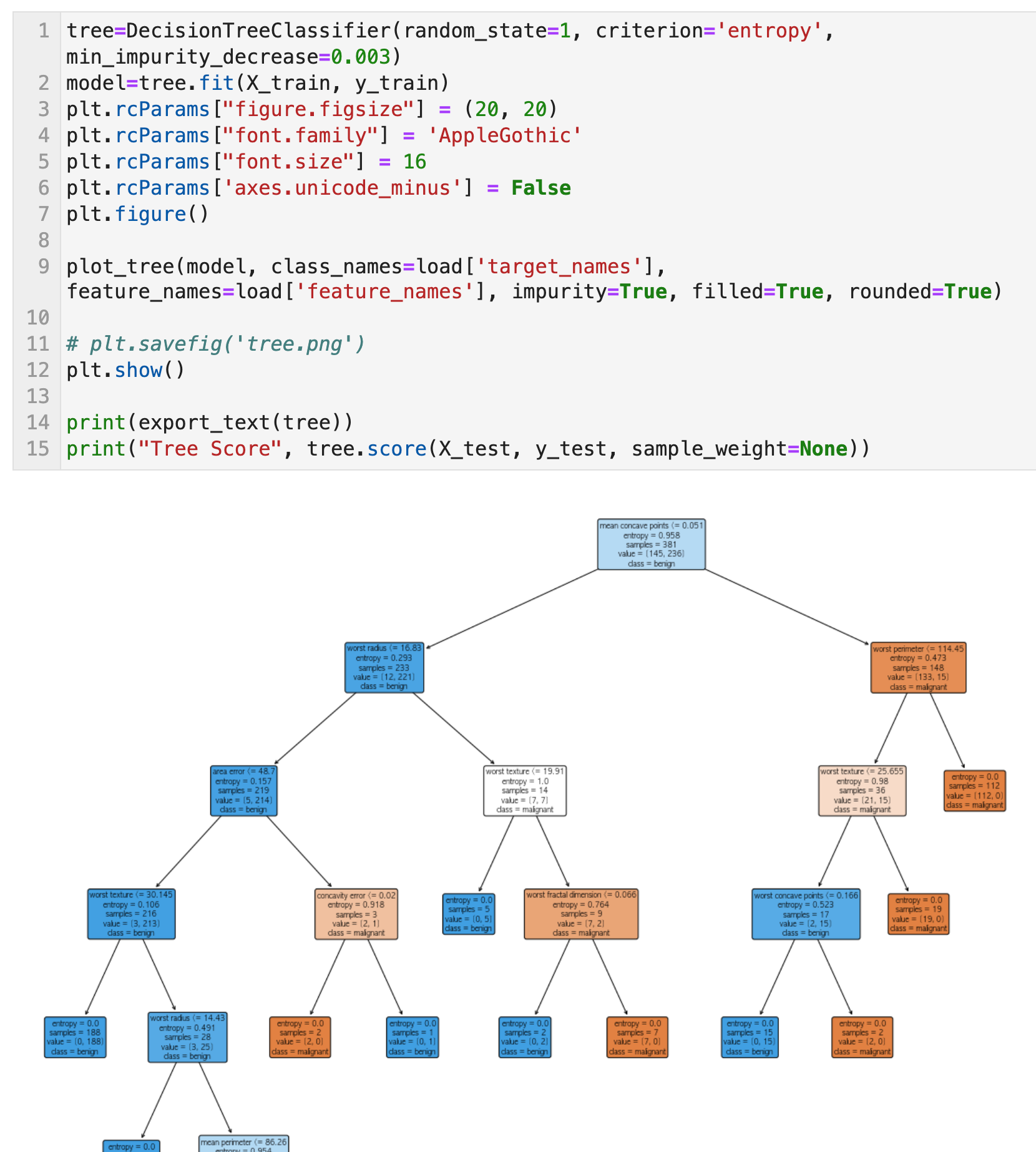
plot_tree에 결정 트리 객체를 입력하면 아래와 같이 plotting이 가능하다. 텍스트로 확인하고 싶으면 export_text를 하면 된다.

Scikit Learn으로 회귀트리 구현하기 -DecisionTreeRegressor()
타겟값이 연속형 변수일 때 사용하는 결정트리이다. 회귀 예제는 다음과 같다. sklearn.tree로부터 DecisionTreeRegressor, plot_tree, export_text 함수들을 import한다. 그리고 X, y 별로 훈련용 데이터셋과 테스트용 데이터셋을 나눈다.

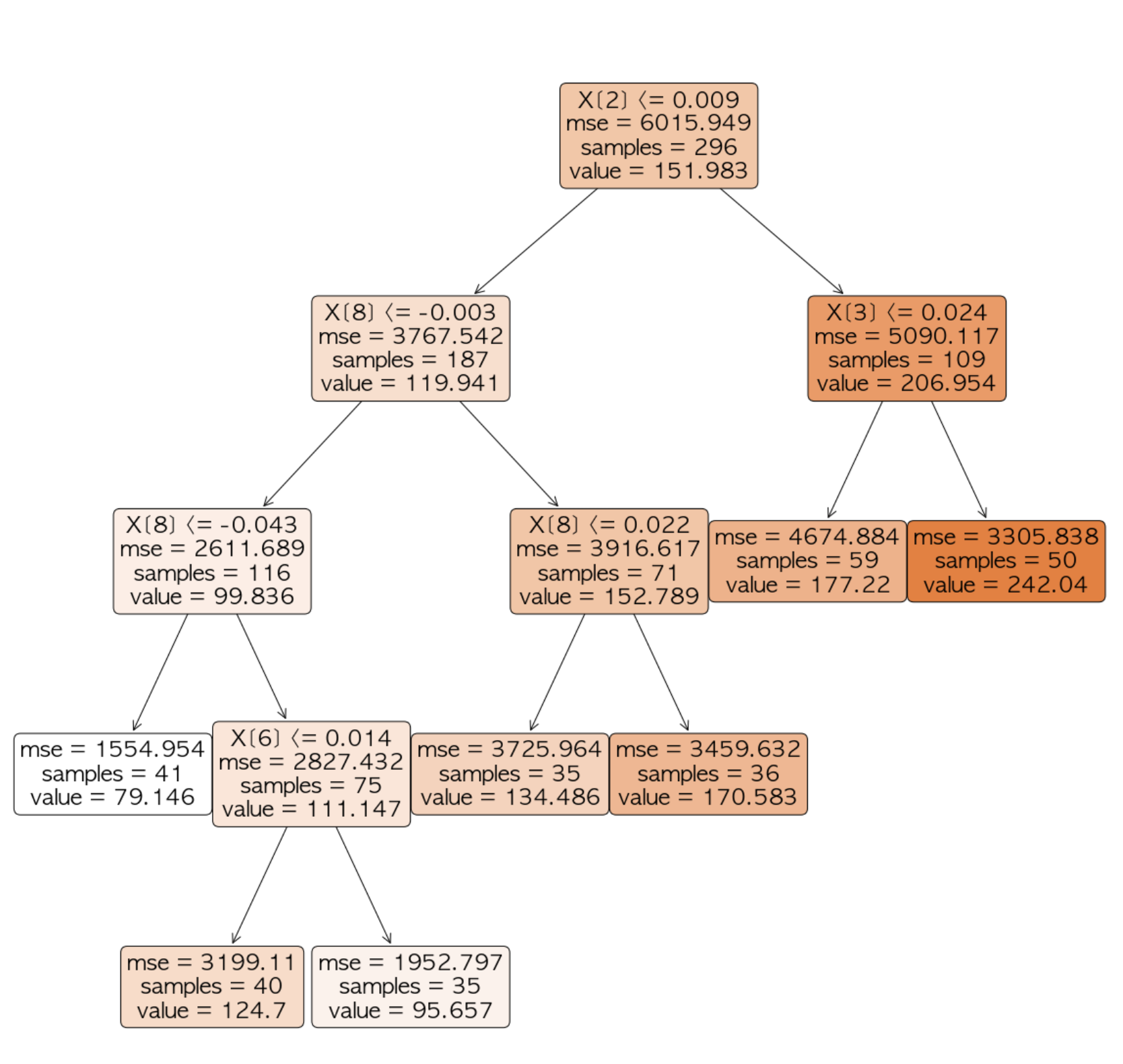

DecisionTreeRegressor()함수로 결정트리를 학습할 방식들을 파라미터로 입력한다. 여기에 들어가는 파라미터들은 아래와 같다. 물론 다 넣을 필요는 없고 학습 결과에 따라서 사용할 파라미터를 선택하고 설정하면 된다.
- criterion: 불순도 척도. 'squared_error', 'friedman_mse', 'absolute_error', 'poisson', default='squared_error'
- 'squared_error': 평균 제곱 오차(MSE), 변수선택 기준으로서의 분산 감소와 동일하다. 각 끝 노드의 평균을 사용한 L2 loss를 최소화한다.
- 'friedman_mse' : 잠재적 분할을 위한 Friedman의 improvement score를 포함하는 MSE.
- 'absolute_error': 오차의 절대값의 평균, 각 끝 노드의 중앙값을 사용한 L1 loss를 최소화 한다.
- 'poisson': 분기를 찾기 위해 포아송 편차 감소를 사용한다.
- splitter: 각 노드의 분할 전략. 최적분할과 최적 랜덤분할. 'best', 'random', default='best'
- max_depth: 트리 깊이의 최대값. 값을 입력하지 않을 경우, 모든 leaf가 pure해질때까지 혹은, 분기된 노드 속 샘플수가 설정한 최소 샘플수(min_samples_split)보다 적게 될때까지 분기한다. 'int값 입력'
- min_samples_split: 분기 할 node 내 샘플의 최소 개수. 최소 개수보다 node 내 샘플 수가 적으면 leaf가 pure하지 않더라도 분기를 멈춘다. float 입력 시, 전체 샘플 개수 대비 float 비율만큼의 개수로 최소 샘플수가 설정된다. 'int 혹은 float값 입력', default=2
- min_samples_leaf: leaf 노드에 있어야 하는 최소 샘플 수. 왼쪽 혹은 오른쪽 branch에 각각 min_samples_leaf만큼 훈련 샘플이 있어야 분기가 된다. 'int 혹은 float값 입력', default=2
- min_weight_fraction_leaf: 모든 샘플의 가중치의 합계의 최소 가중치의 비율, 입력되지 않으면 모든 샘플의 가중치는 동일하다. 'float 입력', default=0.0
- max_features: 최적의 분할을 찾기 위해 고려하는 feature의 개수. 'int or flaot값', 'auto', 'sqrt', 'log2', default=None.
- random_state: 추정기의 무작위성 제어. 'int 입력', default=None
- max_leaf_nodes: 최대 노드 수. default=None
- min_impurity_decrease: 최소 불순도 감소값 이하인 경우에는 분기가 일어나지 않는다. 'float', default=0.0
- ccp_alpha: 최소 비용-복잡성 가지치기에 사용되는 복잡도 매개변수. ccp_alpha보다 작은 비용-복잡도를 가진 하위 트리 중에 비용-복잡도가 가장 큰 하위 트리가 선택된다.
tree.score(X, y)로부터 얻는 값은 해당 모델의 결정계수이다. 모델의 설명력을 의미한다. 회귀트리의 경우, 훈련셋과 테스트셋의 설명력이 40~50%로 낮게 나타났다. 이럴 땐 파라미터를 조정하거나 아예 다른 학습 방식을 강구해야 한다.
안드레아스 뮐러, 세라 가이도, 파이썬 라이브러리를 활용한 머신러닝 번역개정판 (서울: 한빛미디어, 2019)
스티븐 마슬랜드, 알고리즘 중심의 머신러닝 가이드 제2판 Machine Learning: An Algorithmic Perspective, Second Edition (경기: 제이펍, 2017)
피터 브루스, 앤드루 브루스, 피터 게데크, 데이터 과학을 위한 통계 2판 (서울: 한빛미디어, 2021)
sklearn.tree.DecisionTreeClassifier, Scikit Learn,
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
'Study history > ADP 실기 합격 기록' 카테고리의 다른 글
| ADP) 3-1. 전처리 1탄 (결측치, 이상값, 클래스 불균형 처리방법들) (5) | 2021.12.02 |
|---|---|
| ADP) 1-3-1. 탐색적 자료 분석: 요약, 기술통계 (평균, 표준편차, 중위수, 사분위수, 변동계수, 최빈값, 그래프, 왜도, 첨도), 줄기잎그림, 도넛차트, 히스토그램, 상자수염 그림 (0) | 2021.12.01 |
| ADP) ADP 실기 기출문제 모음 (17, 18, 19, 20, 21, 22, 23, 24, 25, 26회) (29) | 2021.11.26 |
| ADP) ADP 실기 준비 - 주제 목록 (0) | 2021.11.25 |
| 30회 ADsP 및 23회 ADP 필기 시험 합격 후기 (+비전공) (0) | 2021.11.16 |



댓글