전처리 1탄에서는 결측치, 이상값, 클래스 불균형 처리 방법들을 다뤘다. 이번 전처리 2탄에서는 수치형 변수변환에 대해 포스팅 하고자 한다. https://lovelydiary.tistory.com/409
ADP) 3-1. 전처리 1탄 (결측치, 이상값, 클래스 불균형 처리방법들)
결측치 처리 방법들 데이터에 있는 결측치들을 처리하는 여러가지 방법들이 있다. 결측값인 채로 처리: 결측값인 채로 모델링 가능한 모델들이 있다. (예: GBDT모델) Zero Imputation: 0으로 대치한다
lovelydiary.tistory.com
변수변환 (Feature Scaling)
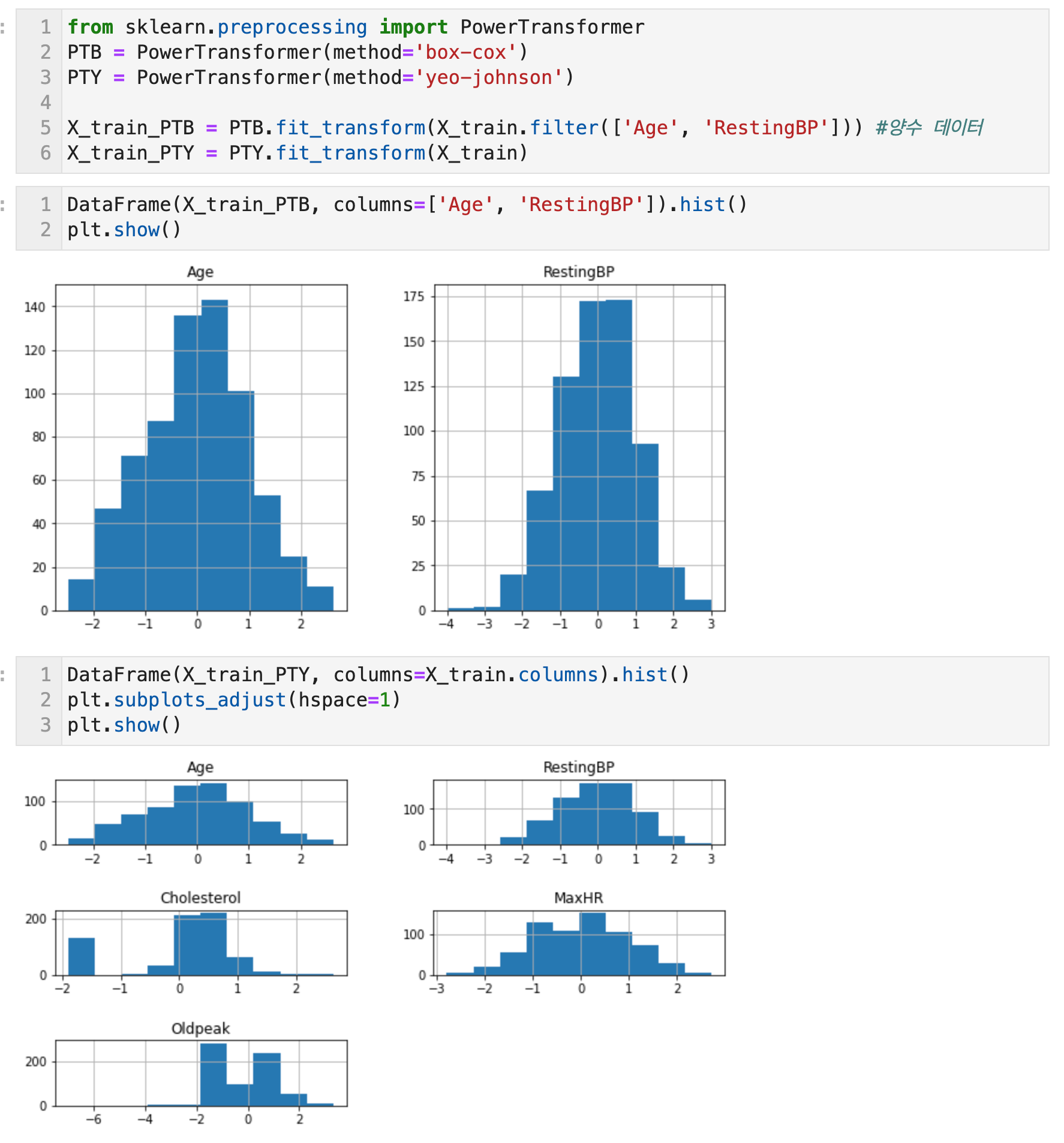
변수변환이란, feature의 스케일을 바꾸는 feature 정규화를 의미한다. 입력 feature들의 스케일이 서로 크게 다른 상황에서 유용하다. 어떤 수치형 feature들은 무한히 증가하기 때문에 선형회귀나 로지스틱 회귀 등과 같이 입력에 대한 평활 함수인 모델은 입력의 스케일에 영향을 받는다. 반면, 트리 기반 모델은 입력의 스케일에 그다지 신경 쓰지 않아도 된다. 모델이 입력 feature의 스케일에 민감하다면 변수 변환이 도움이 될 수 있다.
일반적으로 변수변환은 각 feature에 대해 개별적으로 수행된다. feature의 유형에 따라 다음과 같은 변수 변환 방법들이 있다.
- 수치형 변수 변환 (*옆의 괄호는 Scikit Learn의 함수명)
- 선형변환: 최소최대 스케일링(MinMaxScaler), 표준화(StandardScaler), 로버스트 스케일링(RobustScaler), 균등분포/RankGauss (QuantileTransformer)
- 비선형변환: 로그변환, 거듭제곱변환(PowerTransformer - Boxcox, YeoJohnson), 정규화(Normalizer - L1, L2, Max)
- 기타: 구간분할 (=이산화, binning), 순위 변환
- 범주형 변수 변환
- 원핫인코딩(One-hot-encoding), 더미코딩(dummy coding), 이펙트코딩(Effect coding), 숫자로 표현된 범주형 특성, 레이블인코딩(Label encoding), 특징 해싱(Feature Hashing)
수치형 변수의 선형변환 - 1) 최소최대 스케일링 (Min-Max Scaling) with MinMaxScaler
최소최대 스케일링(Min-Max Scaling)은 모든 특성이 정확하게 0과 1사이에 위치하도록 데이터를 정규화한다. 2차원 데이터셋일 경우 모든 데이터가 x축의 0과 1 y축의 0과 1 사이의 사각 영역에 담기게 된다. 정규화 공식은 (데이터 값-최소값)/(최대값-최소값) 이다. Scikit Learn의 MinMaxScaler 함수를 사용해서 구현할 수 있다.
변환 후의 평균이 정확히 0이 되지 않고 이상치의 악영향을 받기 쉽다는 단점이 있어서 표준화 (Standardization) 방법이 더 자주 쓰인다. 한편 이미지 데이터의 픽셀값과 같이 처음부터 0~255로 범위가 정해진 변수는 최소-최대 스케일링을 이용하는게 더 자연스러울 수 있다.
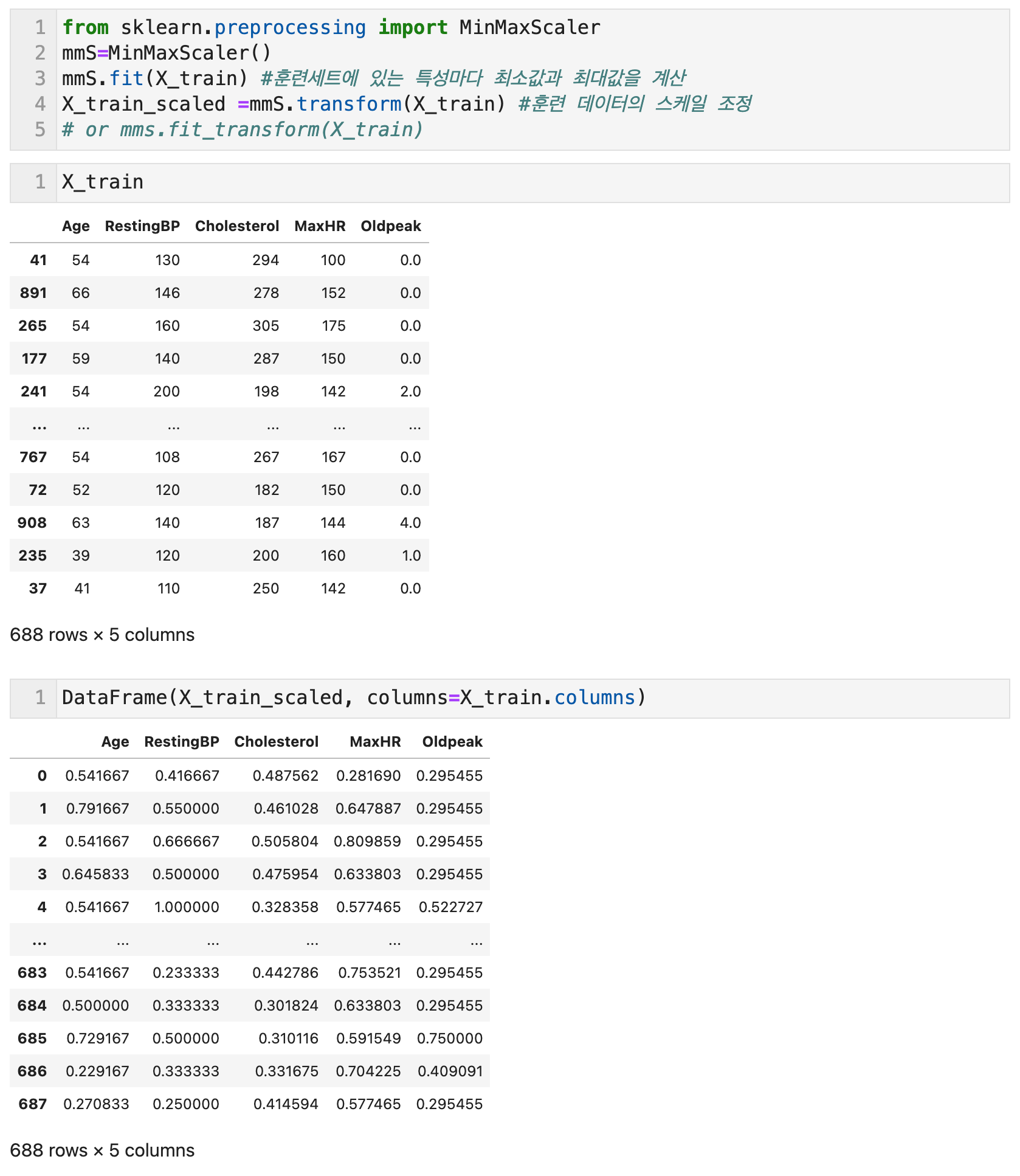
MinMaxScaler()의 객체에 .fit(데이터)를 하면 객체에 데이터에 있는 특성마다의 최소값과 최대값을 계산한다. 이를 바탕으로 .transform(데이터)를 동일한 객체에 적용하면, 스케일을 조정한 데이터 결과물이 나오게 된다. 왼쪽 위에서 원본값과 스케일링한 값을 비교할 수 있다.
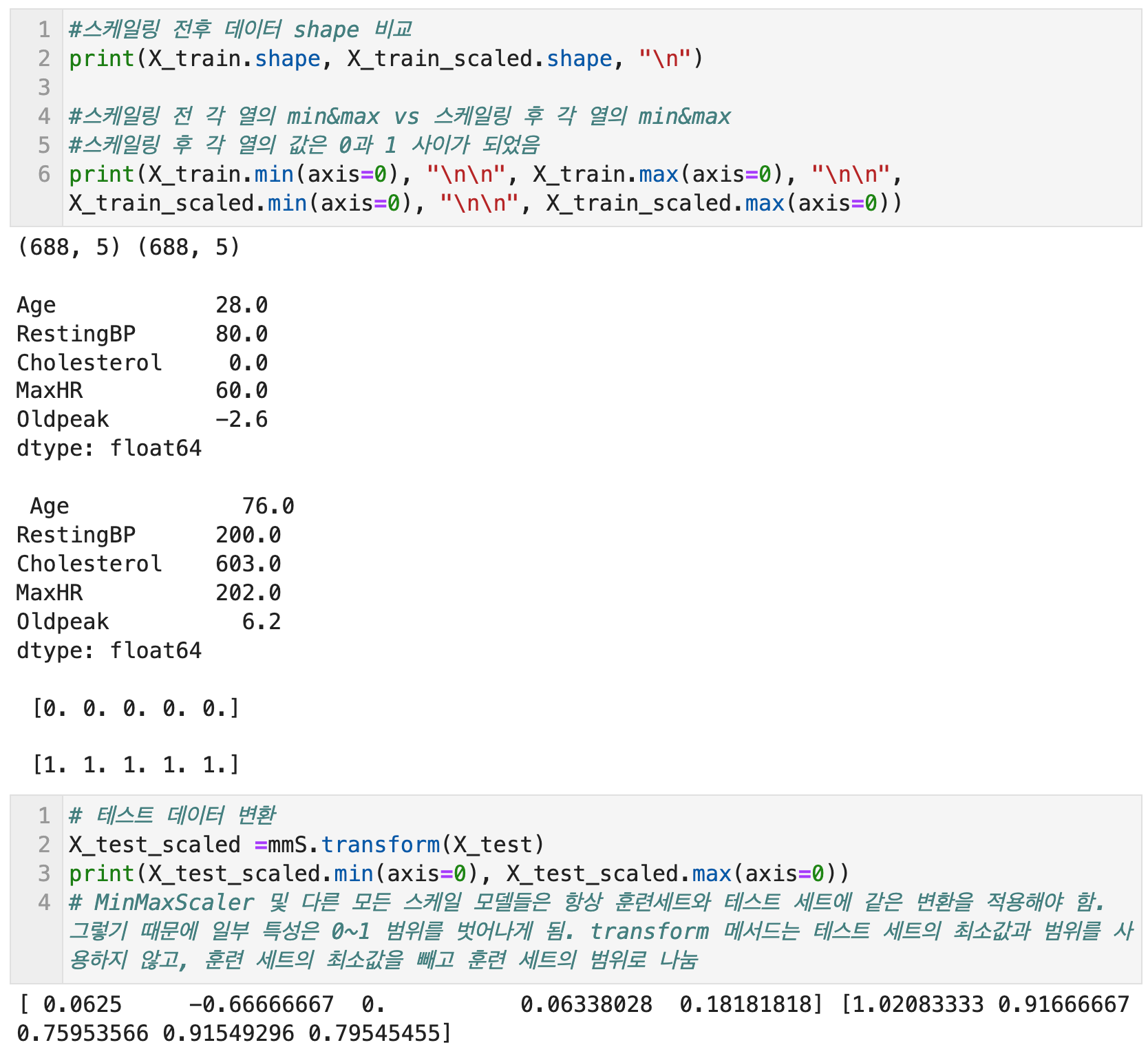
스케일링 전후 데이터의 shape을 비교하면, 행열의 숫자가 동일한 것을 확인할 수 있다. 또한 스케일링 전 데이터의 최소값과 최대값을 열별로 확인하면 값들이 다양한 것을 볼 수 있는데, 스케일링 후에는 모든 열(feature)의 최소값이 0, 최대값이 1로 스케일링된 것을 확인할 수 있다.
최소최대 스케일링을 포함하여 다른 모든 스케일링을 진행할 때 주의할 점은 항상 훈련세트와 테스트 세트에 같은 변환을 적용해야 한다는 점이다. 이 경우, 테스트 세트의 최소, 최대값이 훈련세트의 값보다 벗어나면 일부 특성은 0~1의 범위를 벗어날 수도 있다.
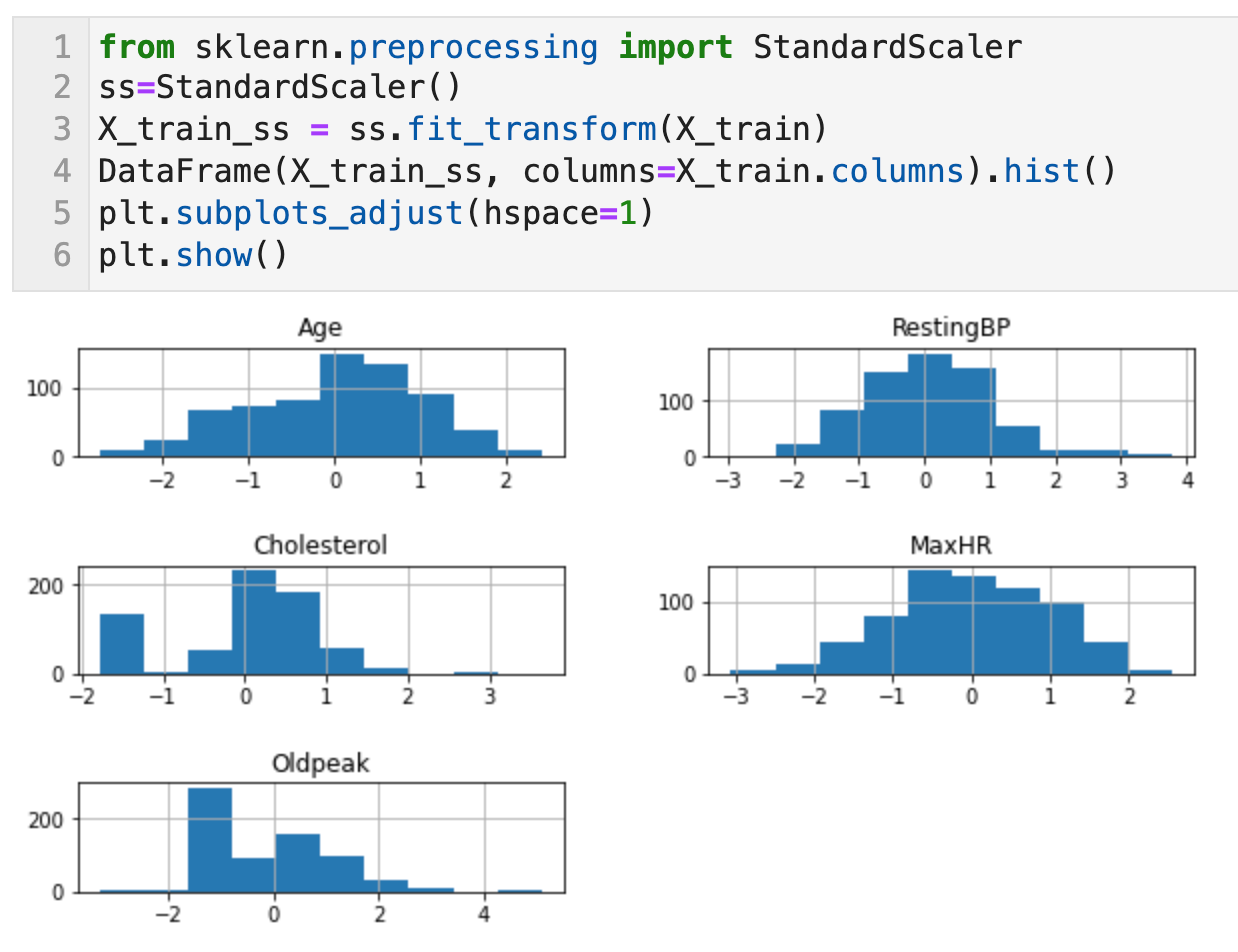
수치형 변수의 선형변환 - 2) 표준화 (Standardization) with StandardScaler
표준화(Standardization)는 variance scaling이라고 불리기도 한다. 곱셈과 덧셈만으로 변환하는 선형변환을 통해 각 특성의 평균을 0, 분산을 1로 변경하여 모든 특성이 같은 크기를 가지게 한다. 그러나 이 방법은 특성의 최소값과 최대값 크기를 제한하지는 않는다. (데이터값-평균)/표준편차로 구하며 이 값을 표준점수 혹은 z-score라고 한다.
선형회귀나 로지스틱 회귀 등의 선형모델에서는 값의 범위가 큰 변수일 수록 회귀계수가 작아지므로 표준화하지 않으면 그런 변수의 정규화가 어려워진다. 신경망에서도 변수들 간의 값의 범위가 크게 차이나는 상태로는 학습이 잘 진행되지 않을 때가 많다.
0과 1 이진변수에 대해서는 표준화를 실시하지 않아도 된다.
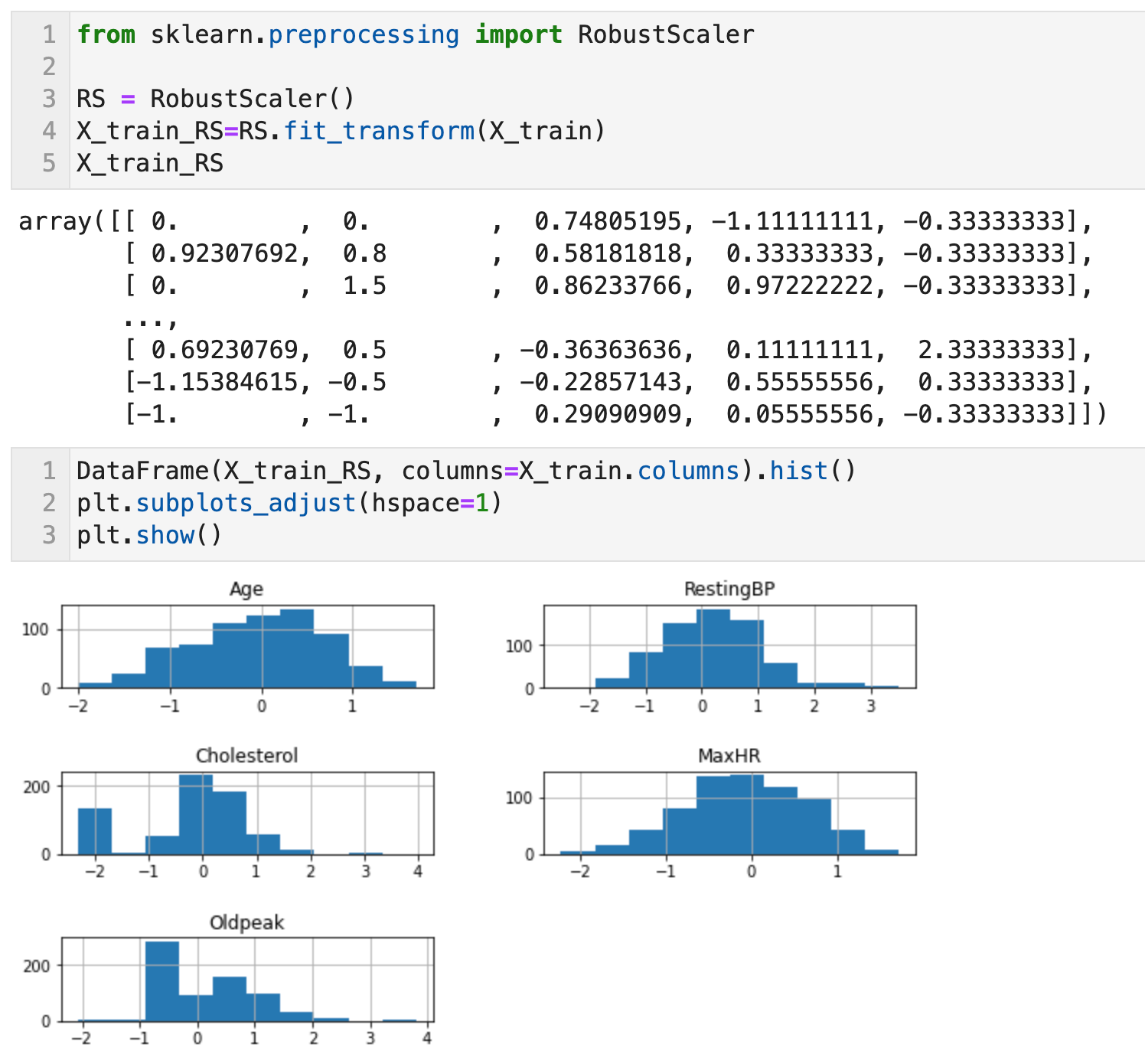
수치형 변수의 선형변환 - 3) Robust Scaling with RobustScaler
특성들이 같은 스케일을 같게 된다는 통계적 측면에서는 표준화와 비슷하지만 평균과 분산 대신 중앙값(median)과 사분위수(quantile)을 사용한다. 이 때문에 RobustScaler는 이상치의 영향을 받지 않는다. (데이터값-중간값)/(3사분위수 - 1사분위수)로 구한다.
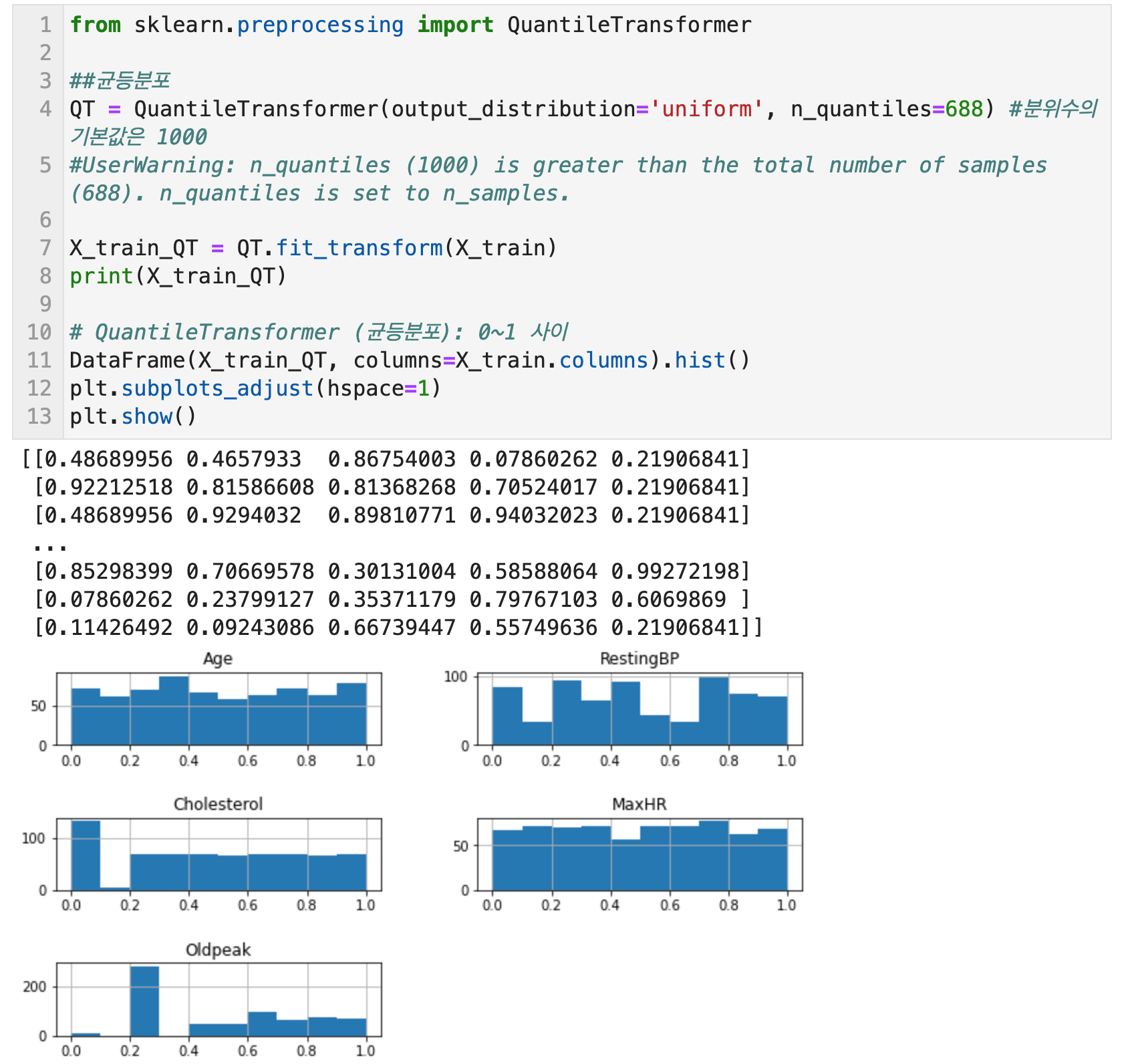
수치형 변수의 선형변환 - 4) 균등분포, 정규분포(RankGauss) with QuantileTransformer
Scikit Learn의 QuantileTransformer로 균등분포와 정규분포로의 선형변환이 가능하다. 균등분포는 1000개의 분위를 사용하여 데이터를 균등하게 배포시키는 방법이다. RobustScaler와 비슷하게 이상치에 민감하지 않으며 전체 데이터를 0과 1사이로 압축한다. 분위수는 n_quantiles 매개변수에서 설정할 수 있으며 기본값은 1000이다. QuantileTransformer(output_distribution='uniform', n_quantiles=688) 식으로 코드를 작성한다. 여기서 output_distribution을 uniform으로 하면 균등분포가 되고, normal로 하면 정규분포가 된다.
RankGauss는 수치형 변수를 순위로 변환한 뒤 순서를 유지한 채 반강제로 정규분포가 되도록 변환하는 방법이다. 신경망에서 모델을 구축할 때의 변환으로서 일반적인 표준화보다 좋은 성능을 나타낸다고 한다.

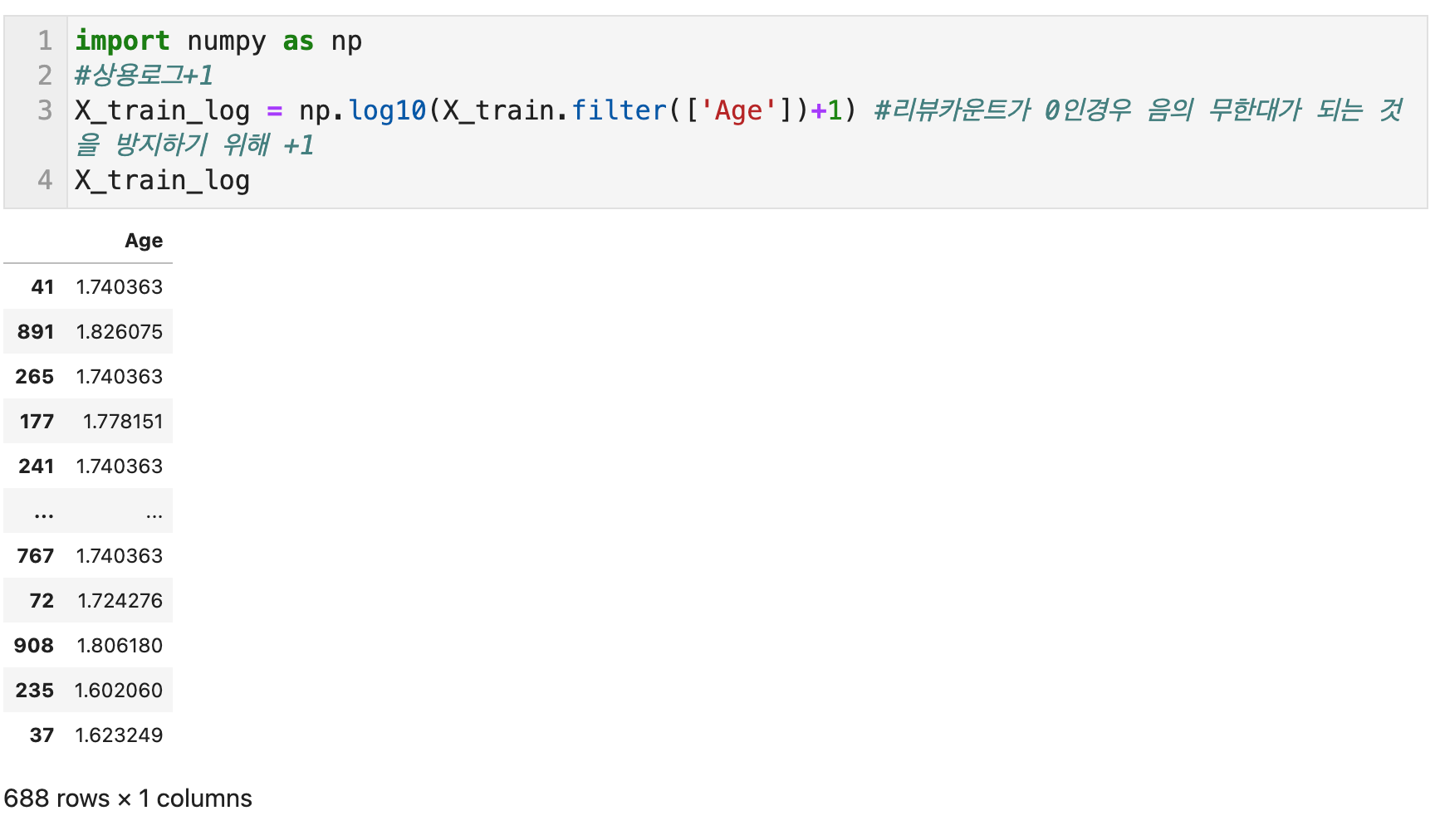
수치형 변수의 비선형변환 - 1) 로그 변환(Log Scaling) with np.log1p
로그함수는 지수함수의 역함수이다. log(x)는 [1,10]의 범위를 [0,1]의 범위로, [10, 100] 범위를 [1,2] 범위로 맵핑한다. 즉 로그함수는 큰수의 범위를 압축하고 작은수의 범위를 확장한다. x가 커질수록 log(x)의 증가는 느려진다. (가로축에서 100-1000까지의 x 값은 세로축 y에서 2-3사이의 좁은 범위로 압축되지만, x값이 100보다 작은 매우 좁은 구간은 세로축에서 넓은 범위에 매핑된다)
로그변환은 두꺼운 꼬리분포(heavy-tailed distribution)를 갖는 양수로 된 데이터를 다루는 강력한 도구이다. 분포에서 값이 높은 쪽에 있는 긴 꼬리를 짧게 압축하고, 낮은 값 쪽의 머리가 길어지게 하기 때문이다. 가우시안 분포보다 꼬리 범위에 더 많은 확률 질량을 가진다.
Box-cox 변환의 매개변수 람다가 0일 때가 로그 변환이다.
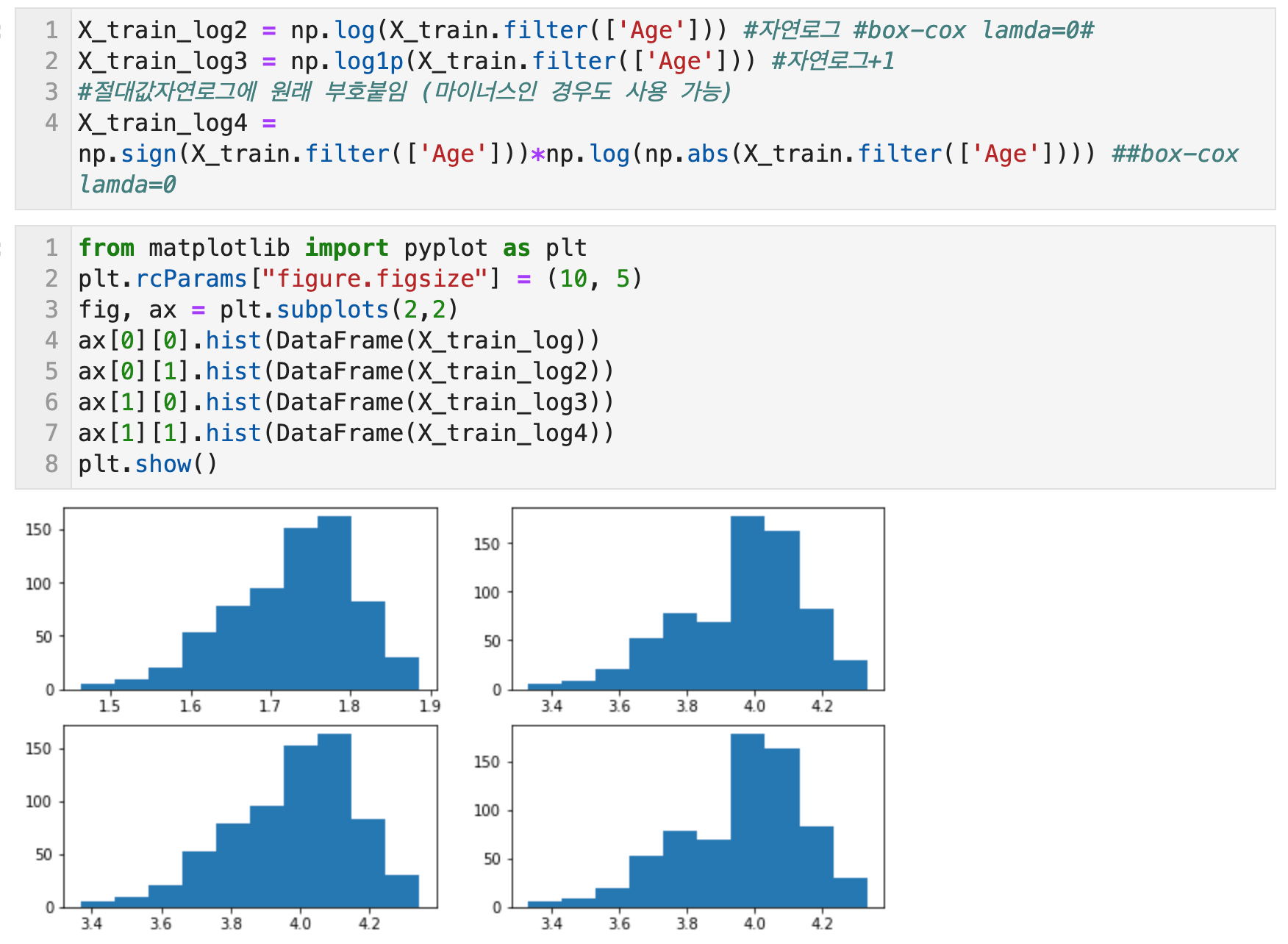
아래는 상용로그, 자연로그, 자연로그+1, 절대값을 씌우고 자연로그 변환 후 원래의 부호를 붙인 경우를 그래프로 비교해본 것이다. 이 중에 일반적으로 파이썬으로 로그 변환에 쓰이는 함수는 np.log1p이다. np는 numpy를 import 할 때 통용되는 alias이다.
수치형 변수의 비선형변환 - 2) 거듭제곱 변환 with PowerTransformer
거듭제곱 변환은 로그변환을 일반화한 것이다. 분산 안정화 변환이라고도 한다. 푸아송 분포는 평균과 분산이 동일한 값을 갖는 두꺼운 꼬리 분포로서 질량 중심이 커질 수록 분산도 커지고 꼬리도 굵어진다. 거듭제곱 변환은 분산이 더이상 평균에 의존하지 않도록 변수의 분포를 바꾼다. 분포의 평균을 나타내는 람다가 증가할수록 분포의 최빈값이 오른쪽으로 이동할 뿐만 아니라 질량이 점점 퍼지면서 분산도 커진다.
Scikit Learn 패키지의 PowerTransformer 함수를 사용하여 구현한다. method 매개변수에 'yeo-johnson', 'box-cox' 알고리즘을 지정할 수 있다. 기본은 'yeo-johnson'이다.
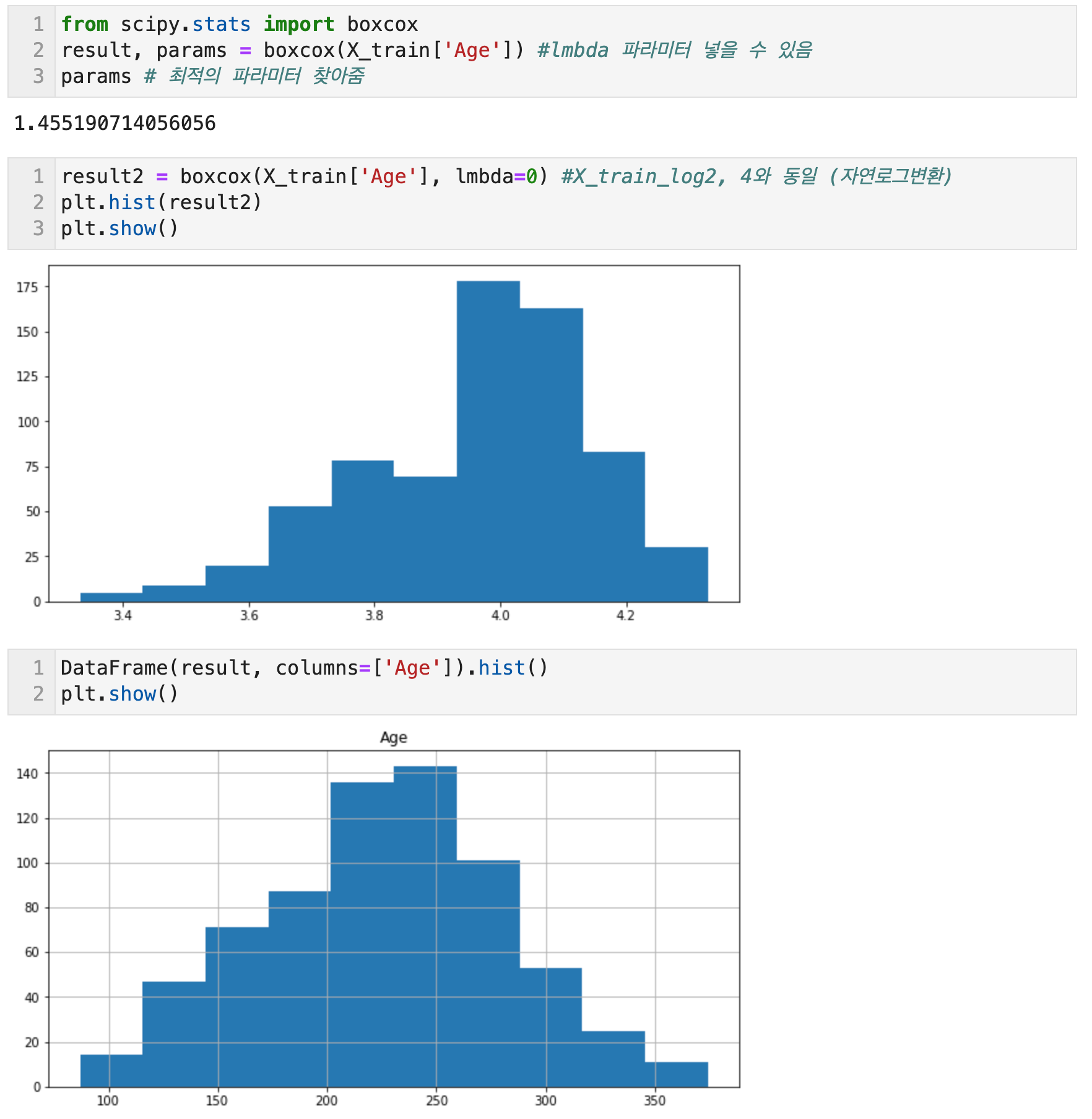
한편, Scipy의 boxcox 함수를 사용하면 result, params = boxcox(data)를 통해 params에 최적의 파라미터가 할당된다.
- Box-cox: 주된 용도는 데이터를 정규분포에 가깝게 만들거나 데이터의 분산을 안정화하는 것으로, 정규성을 가정하는 분석법이나 정상성을 요구하는 분석법을 사용하기에 앞서 데이터의 전처리에 사용한다. 데이터가 모두 양수여야 한다는 전제조건이 있다. 보통은 데이터의 최소값이 양수가 되도록 어떤 값을 더해서 밀어주는 식(shift)으로 해결한다. 최대우도법이나 베이지안 기법을 통해 최적의 파라미터 람다의 값을 정할 수도 있다.
- Yeo-Johnson: Box-cox의 shift 방법이 마음에 들지 않는다면 실수 전체에 대해 일반화된 여-존슨 변환을 고려해볼 수 있다. 이 경우, 데이터가 양수/음수여도 된다.
수치형 변수의 비선형변환 - 3) 정규화(Normalizing, Regularization) with normalize
정규화는 머신러닝에서 overfitting을 방지하는 중요한 기법 중 하나로서 모델을 구성하는 coefficient들이 학습 데이터에 overfitting되지 않도록 정규화 요소를 더해 주는 것이다.
Norm 계산의 결과로 나오는 수치는 원점에서 벡터 좌표까지의 거리이며 이를 manitude라고 부른다. L1, L2 정규화는 이같은 L1, L2 norm을 사용한 값들을 더해주는 것이다. 따라서 overfitting이 심하게 발생할 수 있는 가능성이 큰 수치에 penalty를 부여한다. L2는 각 vector에 대해 unique한 값이 출력되는 반면 L1은 경우에 따라 특정 feature없이도 같은 값을 낼 수 있다. 이에 따라 L1 norm은 feature selection에 사용 가능하며 특정 feature들을 0으로 처리해버리는 것이 가능하여 새당 coefficient들이 sparse한 형태를 가질 수 있게 된다.
- ||x||1 = L1 norm: 벡터 간의 거리를 절대값으로 구함 -> 맨해튼 거리, L1 loss: 타겟값과 예측값의 차를 절대값으로 구한 것
- ||x||2 = L2 norm: 벡터 간의 거리 -> 유클리드 거리, L2 loss: 타겟값과 예측값의 차의 제곱
선형 회귀 모델에서 L1 규제를 주는 것이 lasso regression(릿지회귀와 동일하지만 𝐿1 norm을 제약한다는 점이 다름), 선형 회귀 모델에서 L2 규제를 주는 것이 Ridge regression(평균제곱오차를 최소화하면서 회귀계수 벡터 β의 𝐿2 norm을 제한하는 기법)이다.
미래 데이터에 대한 오차의 기대값은 Bias와 Variance로 분해할 수 있는데 정규화는 variance를 감소시켜 일반화 성능을 높이는 기법이다. 이 과정에서 bias가 증가할 수는 있다.
파이썬에서 정규화는 Scikit Learn의 normalize 함수로 구현할 수 있다.
- 일반적으로 2차원 행렬과 함께 사용되며 L1, L2 정규화 옵션을 제공한다.
- norm 매개변수는 L1, L2, Max 세가지 옵션을 제공하며 유클리디안 거리를 의미하는 L2가 기본 값이다. StandardScaler, MinMaxScaler, RobustScaler는 열의 통계치를 이용하지만, normalize는 행마다 각기 정규화된다.
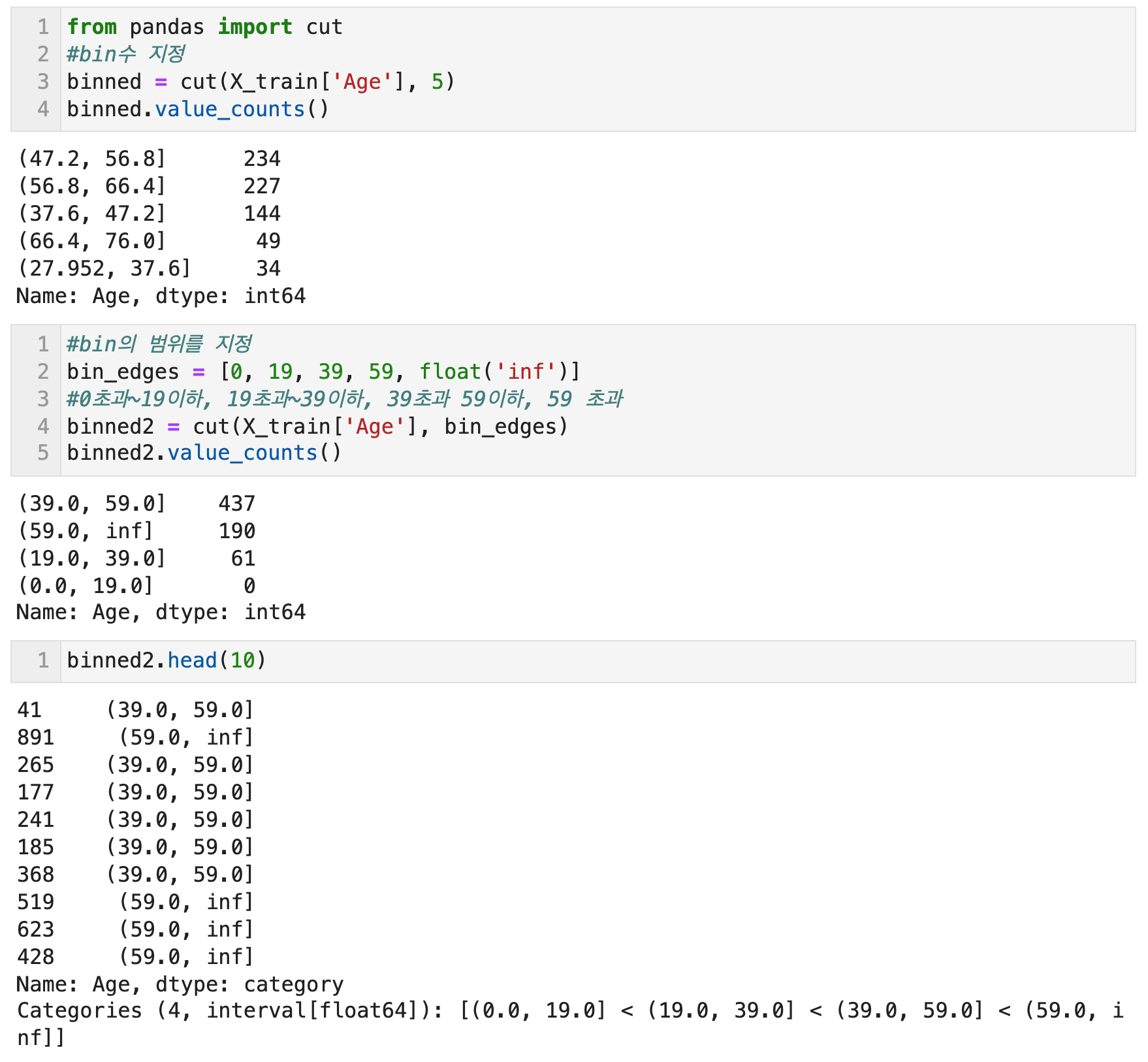
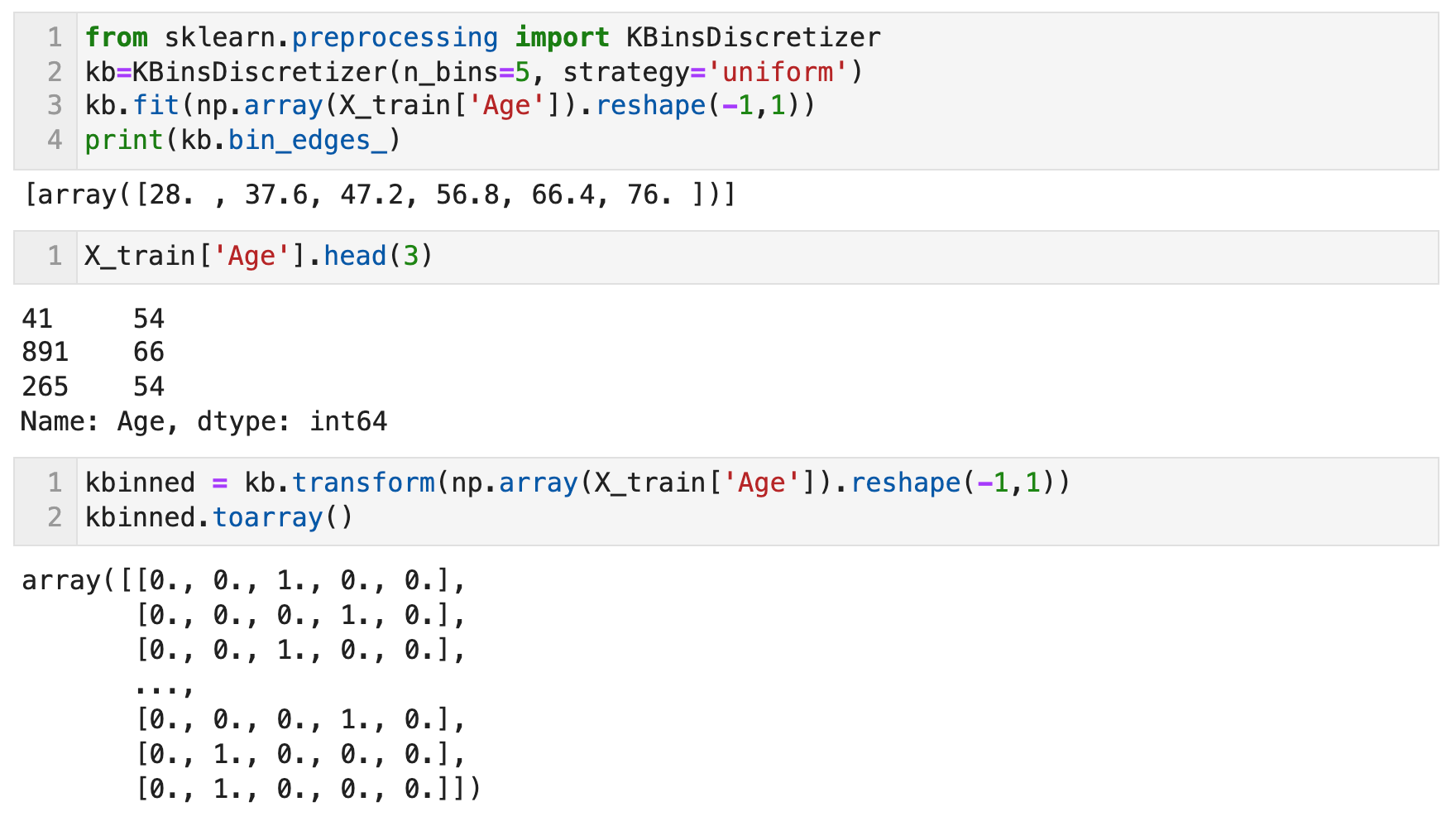
수치형 변수 기타 - 1) 구간분할, 이산화 (Binning) with cut, KBinsDiscretizer
구간분할 혹은 이산화는 수치형 변수를 구간별로 나누어 범주형 변수로 변환하는 방법이다. 구간분할을 하면 순서가 있는 범주형 변수가 되므로 순서를 그대로 수치화할 수도 있고 범주형 변수로서 원핫 인코딩 등을 적용할 수도 있다. 구간의 범주마다 다른 변수값을 집계할 수 있는 범주형 변수로 사용할 수 있다.
같은 간격으로 분할하는 방법, 분위점을 이용하여 분할하는 방법, 구간 구분을 지정하여 분할하는 방법 등이 있다.
pandas의 cut 함수로, 지정한 bins 수만큼 균일한 범위로 데이터를 분할 하거나 지정한 범위대로 데이터를 분할 할 수 있다. Scikit Learn의 KBinsDiscretizer 함수를 이용하면, 지정한 bins 수대로 데이터를 분할한 후 각 구간 별로 원핫인코딩을 적용할 수 있다. 구간마다 하나의 새로운 특성이 생기므로 희소 행렬이 만들어진다.
수치형 변수 기타 - 2) 순위로 변환 with rank
수치형 변수를 대소 관계에 따른 순위로 변환하는 방법이다. 단순히 순위로 바꾸는 것 외에, 순위를 행 데이터의 수로 나누면 0부터 1의 범위에 들어가고, 값의 범위가 행 데이터의 수에 의존하지 않으므로 다루기 쉽다. 수치의 크기나 간격 정보를 버리고 대소 관계만을 얻어내는 방법이다.
x = [10, 20, 30, 0, 40, 40]
import pandas as pd
pd.Series(x).rank() # 랭크 시작은 1, 같은 순위가 있을 경우 평균 순위가 됨 (5+6의 평균)
범주형 변수 변환은 다음 포스팅에서 이어서 정리한다. https://lovelydiary.tistory.com/419
ADP) 3-1. 전처리 3탄 (변수 변환; Feature Scaling 총정리 - 수치형/범주형)
https://lovelydiary.tistory.com/417 ADP) 3-1. 전처리 2탄 (변수 변환; Feature Scaling 총정리 - 수치형/범주형) 변수변환 (Feature Scaling) 변수변환이란, feature의 스케일을 바꾸는 feature 정규화를 의..
lovelydiary.tistory.com
가도와키 다이스케, 사카타 류지, 호사카 게이스케, 히라마쓰 유지, 데이터가 뛰어노는 AI 놀이터, 캐글 (서울: 한빛미디어)
안드레아스 뮐러, 세라 가이도, 파이썬 라이브러리를 활용한 머신러닝 번역개정판 (서울: 한빛미디어, 2019)
앨리스 젱, 아만다 카사리, 피처 엔지니어링 제대로 시작하기 (서울: 에이콘, 2019)
웨스 맥키니, 파이썬 라이브러리를 활용한 데이터 분석 (서울: 한빛미디어, 2016)
'Study history > ADP 실기 합격 기록' 카테고리의 다른 글
| ADP) 3-1. 전처리 3탄 (변수 변환; Feature Scaling 총정리 - 수치형/범주형) (0) | 2021.12.12 |
|---|---|
| ADP) 파이썬으로 푸는 ADP실기 데이터 분석전문가 모의고사 1회-(1) (5) | 2021.12.10 |
| ADP) 3-4. 파이썬 그래프 총정리 - 1탄: 점그래프, 선그래프, 점선그래프, 막대그래프, 누적막대그래프 (0) | 2021.12.02 |
| ADP) 3-3. 파이썬으로 리샘플링, 데이터분할 - 부트스트랩, 일반적 데이터 분할(훈련/테스트), 홀드아웃방법, K-fold 교차분석 (0) | 2021.12.02 |
| ADP) 3-2. 파이썬으로 표본 추출: 단순랜덤 추출법, 계통추출법, 집락추출법, 층화추출법 (2) | 2021.12.02 |




댓글