『ADP 실기 데이터 분석 전문가』 모의고사 1회
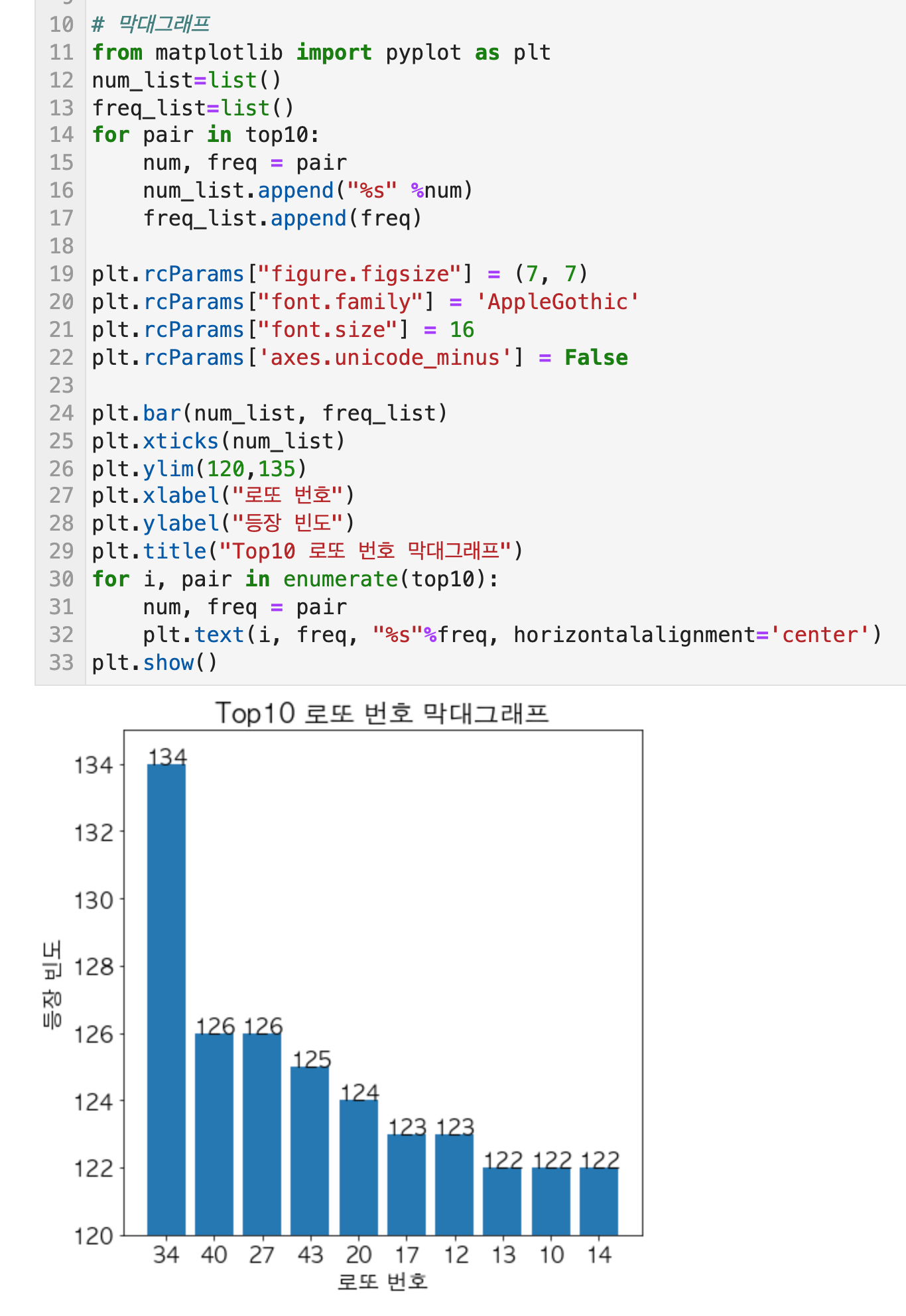
정형 데이터마이닝 Q1) 연관규칙분석을 수행하기 위해 lotto 데이터셋을 transaction 데이터로 변환하시오. 단, 본 분석에서 로또번호가 추첨된 순서는 고려하지 않고 분석을 수행하도록 한다. 그리고 변환된 데이터에서 가장 많이 등장한 상위 10개의 로또번호를 막대그래프로 출력하고 이에 대해 설명하시오.
R에는 as(data, 'transactions')라는 형태로 간편하게 데이터 구조를 트랜잭션 데이터로 변환할 수 있는데, 파이썬에는 이런 함수가 없다. 그래서 최대한 비슷하게 모양을 만들어보았다.
pandas의 read_csv 함수로 csv파일을 데이터프레임으로 가지고 오고, numpy의 array 함수로 각 회차 로또 번호들만 각각 하나의 array로 갖는 2차원 배열을 만들었다. 그리고 아래와 같이 transcation_id와 item으로 열이름을 정하고 데이터프레임을 만들었다.

다음으로 각 로또번호들이 몇번 추첨되었는지 빈도를 확인하기 위해 collections 패키지의 Counter 함수를 사용하였다. Counter(로또번호 배열 혹은 리스트)를 넣으면 딕셔너리 형태로 각 번호가 카운트된다. {'로또번호 1':10, '로또번호 2':30...} 이런 식이다. 그래서 만들어진 전체 num_dict에서 빈도수 top10을 뽑기 위해 most_common함수를 사용할 수 있다. 혹은 이 딕셔너리를 데이터프레임으로 만들어서 'freq' 빈도 순으로 내림차순하여 전체 숫자와 빈도수가 있는 데이터프레임으로 만들 수도 있다.

그리고 상위 10개의 숫자와 그 숫자의 추첨 빈도수를 가지는 막대 그래프를 그린다.
정형 데이터마이닝 Q2) 변환한 데이터에 대해 apriori함수를 사용하여 다음 괄호 안의 조건을 반영하여 연관규칙을 생성하고, 이를 ‘rules_1’이라는 변수에 저장하여 결과를 해석하시오. (최소 지지도 : 0.002, 최소 신뢰도 : 0.8, 최소조합 항목 수 : 2개, 최대조합 항목 수 : 6개) 그리고 도출된 연관규칙들을 향상도를 기준으로 내림차순 정렬하여 상위 30개의 규칙을 확인하고, 이를 데이터프레임으로 변환하여 csv파일로 출력하시오.
R에서는 arules 패키지에 있는 apriori 함수를 통해 연관성 분석을 진행하는데, 파이썬에서는 이 패키지가 없기 때문에 동일한 apriori 알고리즘을 사용하는 mlxtend라는 패키지를 사용해서 분석을 진행하였다. 연관규칙을 찾기 위해 mlxtend 패키지에서 사용한 함수는 TransactionEncoder, apriori, association_rules이다.

TransactionEncoder 함수 객체에 데이터를 fit, transform함으로써 Boolean array를 얻고 이를 데이터프레임으로 만든 다음 apriori 함수에 최소 지지도 파라미터와 함께 실행시키면 해당 최소 지지도를 충족하는 빈발항목집단들이 생성된다. 이를 association_rules함수에 신뢰도(confidence) 혹은 향상도를 적고 최소값을 파라미터로 입력하여 실행하면 이를 충족하는 연관규칙들이 생성된다. 그 다음 빈발집합의 항목 수를 query를 통해 조작하고, sort_values를 통해 lift 기준 내림차순으로 정리하면 최종 결과물이 완성된다.

apriori 알고리즘은 최소 지지도보다 큰 지지도 값을 갖는 품목의 집합을 빈발항목집합이라 하여 최소 지지도 이상의 빈발항목집합을 찾은 후 그것들에 대해서만 연관규칙을 계산하는 알고리즘이다. mlxtend 패키지의 apriori함수는 apriori 알고리즘을 파이썬 코드로 구현한 패키지이며, apriori(데이터, 파라미터)의 기본 형태로 연관규칙을 찾아낼 수 있다. apriori 함수 내에서 최소 지지도와 컬럼명을 사용할지 여부를 파라미터로 지정할 수 있다. 최소 신뢰도, 최소 향상도를 파라미터로 지정하기 위해서는 association_rules(데이터, 파라미터) 함수를 사용하여 metric='기준', min_threshold='기준의 최소값'의 파라미터들을 설정할 수 있다. 규칙 내 항목 수를 기준으로 데이터를 조작하기 위해서는 조건절(antecedents)과 결과절(consequents)의 len값을 갖는 새로운 컬럼들을 만들고 이 컬럼들의 값에 따라 데이터를 sorting하면 최소조합항목수와 최대 조합항목수를 충족하는 데이터를 얻을 수 있다. lift를 기준으로 내림차순 정렬을 위해서서는 데이터프레임 객체에 .sort_values 함수를 사용하였다. 이렇게 정리된 데이터프레임을 rules_1이라는 변수에 담아서 pandas의 .to_csv 함수를 통해 'rules_1.csv'라는 파일로 출력하였다.
정형 데이터마이닝 Q3) 생성된 연관규칙 'rules_1'에 대한 정보를 해석하고, 1)번 문제를 통해 확인했을 때 가장 많이 추첨된 번호가 우측항에 존재하는 규칙들만을 ‘rules_most_freq’라는 변수에 저장하시오. 그리고 해당 규칙들을 해석하여 인사이트를 도출한 후 서술하시오.
위의 결과에서 최소지지도, 신뢰도는 각각 0.002, 0.8, 최소조합 항목 수는 2개, 최대조합 항목 수는 6개로 설정하여 분석을 실시했으며, 총 679개의 연관규칙이 생성되었다. 지지도(support)를 기반으로 해석할 경우에는 좋은 규칙, 불필요한 규칙을 구분하는 기준으로 사용하고, 신뢰도(confidence)는 값이 높을 수록 유용할 규칙일 가능성이 높다. 향상도(lift)가 1인 경우, 조건절(antecedents)과 결과절(consequents)의 조합 항목은 연관이 없고, 향상도가 1보다 크면 클수록 연관이 있음을 알 수 있다. 향상도가 9.65로 계산된 맨 앞의 4개 연관규칙들은 매우 연관성이 높은 우수한 규칙으로 판단할 수 있다. 예를 들어 (28,7,23) 숫자들이 추첨될 경우, (9)가 같이 추첨될 확률이 매우 높은 것이다.
총 679개의 연관규칙이 도출되었으며, 그 중 632개의 규칙은 4개의 로또번호로 구성되었고 47개의 규칙은 5개의 번호로 구성되었다.규칙들에 대한 향상도의 최소값은 6.410으로 꽤 높게 나타났으며, 추첨번호들의 교집합 확률을 의미하는 지지도의 평균은 0.002364로 나타났다. 트랜잭션 데이터의 개수는 859개이며, 트랜잭션 데이터는 859회 동안의 로또 당첨번호들을 의미한다.
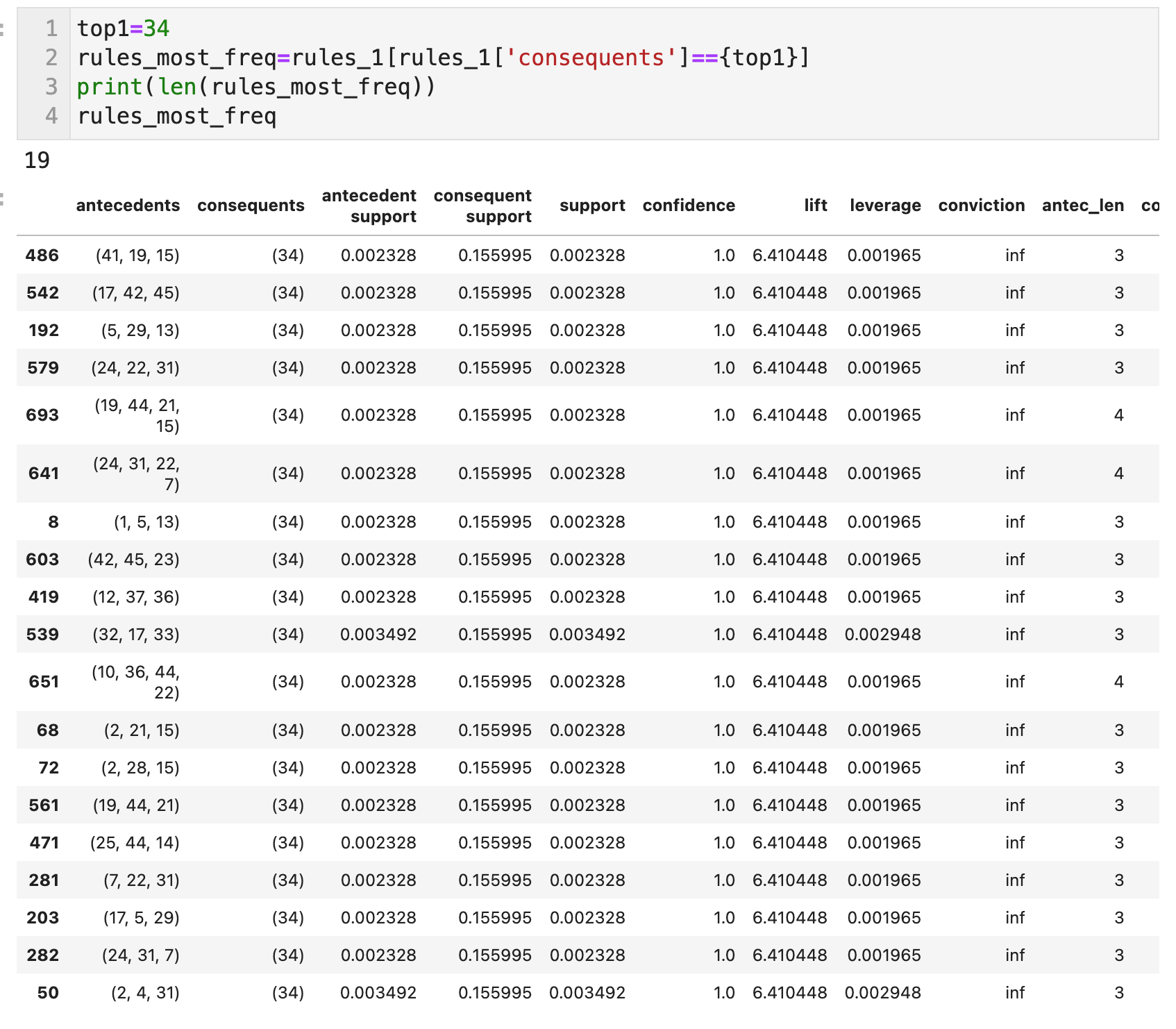
가장 많이 추첨된 번호 34가 우측항에 존재하는 규칙들은 총 19개가 도출되었다. 첫번째 줄의 규칙을 확인해 보면, {41, 19, 15}번과 {34}번이 함께 추첨될 확률은 지지도를 확인한 결과, 0.002328이며 약 0.2%에 해당한다. 이 규칙의 향상도는 6.410448로 이는 {34}만 추첨됐을 때보다 {41, 19, 15}번이 뽑히고 {34}도 뽑힐 확률이 약 6배 높다는 것을 의미한다. 하지만 이러한 규칙들은 로또번호가 추첨되는 순서를 고려하지 않고 단순히 조합에 대한 확률만을 고려한 규칙이므로 향상도가 높은 숫자들의 조합이 로또 추첨번호가 될 가능성이 높은 것은 아니다.
『ADP 실기 데이터 분석 전문가』 참고자료실, http://www.dataedu.kr/data/adpbook_data.php
Association Rules Generation from Frequent Itemsets, http://rasbt.github.io/mlxtend/user_guide/frequent_patterns/association_rules/?#confidence




댓글