ADP) 3-1. 전처리 3탄 (변수 변환; Feature Scaling 총정리 - 수치형/범주형)
지난 전처리 2탄에서 다룬 수치형 변수변환 방법들에 이어서, https://lovelydiary.tistory.com/417
ADP) 3-1. 전처리 2탄 (변수 변환; Feature Scaling 총정리 - 수치형/범주형)
변수변환 (Feature Scaling) 변수변환이란, feature의 스케일을 바꾸는 feature 정규화를 의미한다. 입력 feature들의 스케일이 서로 크게 다른 상황에서 유용하다. 어떤 수치형 feature들은 무한히 증가하
lovelydiary.tistory.com
이번에는 전처리 3탄으로서 범주형 변수변환 방법들을 정리하는 포스팅이다. 변수 변환 방법들 전체 목차는 아래와 같고, 이번 포스팅에서는 범주형 변수 변환을 다룬다.
범주형 변수 변환 (Categorical feature)
특정 애플리케이션에 가장 적합한 데이터 표현을 찾는 것을 특성 공학 (feature engineering)이라고 한다. 올바른 데이터 표현은 지도 학습 모델에서 적절한 매개변수를 선택하는 것보다 성능에 더 큰 영향을 미친다. 여기서는 범주형 특성 (categorical feature) 혹은 이산형 특성 (discrete feature)를 변환하는 방법들을 살펴보려고 한다.
GBDT와 같이 결정트리에 기반을 두는 모델에서는 레이블 인코딩으로 범주형 변수를 변환하는 게 가장 편리하지만, 타겟 인코딩이 더 효과적일 때도 많다. 다만 타겟 인코딩은 데이터 정보 누출의 위험이 있다. 원핫인코딩이 가장 전통적인 방식이고, 신경망의 경우에는 임베딩 계층을 변수별로 구성하는게 조금 번거롭지만 유효하다.
- 범주형 변수 변환
- 원핫인코딩(One-hot-encoding), 더미코딩(dummy coding), 이펙트코딩(Effect coding), 숫자로 표현된 범주형 특성, 레이블인코딩(Label encoding), 특징 해싱(Feature Hashing), 빈도인코딩(Frequency encoding)
범주형 변수 변환 - 1) 원핫인코딩 (One-hot-encoding) with get_dummies, OneHotEncoder, ColumnTransformer
One-out-of-N encoding, 가변수(dummy variable)라고도 한다. 범주형 변수를 0 또는 1 값을 가진 하나 이상의 새로운 특성으로 바꾼 것이다. 0과 1로 표현된 변수는 선형 이진 분류 공식에 적용할 수 있어서 개수에 상관없이 범주마다 하나의 특성으로 표현한다.
원핫인코딩은 통계학의 dummy coding과 비슷하지만 완전히 같지는 않다. 간편하게 하려고 각 범주를 각기 다른 이진 특성으로 바꾸었기 때문이다. 이는 분석의 편리성 (데이터 행렬의 랭크 부족 현상을 피하기 위함) 때문이다.
훈련데이터와 테스트데이터 모두를 포함하는 df를 사용해서 get_dummies 함수를 호출하든지 또는 각각 get_dummies를 호출한 후에 훈련 세트와 테스트 세트의 열이름을 비교해서 같은 속성인지를 확인해야 한다.
특징의 개수가 범주형 변수의 레벨 개수에 따라 증가하기 때문에 정보가 적은 특징이 대량 생성돼서 학습에 필요한 계산 시간이나 메모리가 급증한다. 따라서 범주형 변수의 레벨이 너무 많을 때는 다른 인코딩 방법을 검토하거나 범주형 변수의 레벨 개수를 줄이거나 빈도가 낮은 범주를 기타 범주로 모아 정리하는 방법을 써야 한다.
구현이 쉽고 가장 정확하며 온라인 학습이 가능한 반면, 계산 측면에서 비효율적이고 범주 수가 증가하는 경우에 적합하지 않고, 선형 모델 외에는 적합하지 않으며, 대규모 데이터셋일 경우 대규모 분산 최적화가 필요하다.
pandas의 get_dummies(데이터) 함수를 사용하거나 scikit learn의 OneHotEncoder 혹은 ColumnTransformer를 사용할 수 있다.
- OneHotEncoder는 모든 특성을 범주형이라고 가정하여 수치형 열을 포함한 모든 열에 인코딩을 수행한다. 문자열 특성과 정수 특성이 모두 변환되는 것이다.

- ColumnTransformer는 범주형 변수에는 원핫인코딩, 수치형 변수에는 스케일링을 적용한다.

범주형 변수 변환 - 2) 더미코딩 (Dummy coding) with get_dummies(drop_first=True)
더미코딩은 pandas의 get_dummies 함수에서 파라미터 drop_first=True를 설정함으로써 구현할 수 있다.
범주형 변수의 레벨이 n개일때 해당 레벨 개수만큼 가변수를 만들면 다중공선성이 생기기 때문에 이를 방지하기 위해 n-1개의 가변수를 만드는 방법을 쓰는 것이 더미코딩이다.

범주형 변수 변환 - 3) 이펙트코딩 (Effect coding)
통계학에서 나온 범주형 변수에 대한 또 다른 변형이다. 더미코딩과 유사하지만 기준 범주가 모두 -1의 벡터로 표현된다는 것이 차이점이다. 선형 회귀 모델의 결과를 해석하기가 더 쉽다. 이펙트 코딩에서는 기준 범주를 나타내는 단일 feature가 없기 때문에 기준 범주의 효과는 다른 모든 범주의 계수의 음수 합계로서 별도로 계산해야 한다.
여러 개의 범주형 변수를 모델에서 다룬다면 이펙트 코딩이든 더미 코딩이든 큰 차이가 없지만, 두 개의 범주형 변수가 상호작용이 있는 경우에는 이펙트 코딩이 더 이점을 가진다. 이펙트 코딩으로 합리적인 주효과와 상호작용의 추정치를 얻을 수 있다. 더미코딩의 경우, 상호작용 추정치는 괜찮지만 주효과는 진짜 주효과가 아니라 simple effect에 더 가깝다.
[참고할 만한 글: https://stats.idre.ucla.edu/other/mult-pkg/faq/general/faqwhat-is-effect-coding/]
범주형 변수 변환 - 4) 숫자로 표현된 범주형 특성 with get_dummies
데이터 취합 방식에 따라 범주형 변수인데 숫자로 인코딩된 경우가 많다. 예를 들어 문자열이 아닌 답안 순서대로 0~8까지의 숫자로 채워지는 설문응답 데이터가 있다. 이 값은 이산적이기 때문에 연속형 변수로 다루면 안된다.
숫자 특성도 가변수로 만들고 싶다면 get_dummies를 사용하여 아래와 같이 적용하면 된다.
- get_dummies(columns=[숫자 특성도 포함하여 인코딩하려는 열을 나열])
- 데이터프레임 단에서 숫자 특성을 str 속성으로 변경해준 뒤 get_dummies 진행

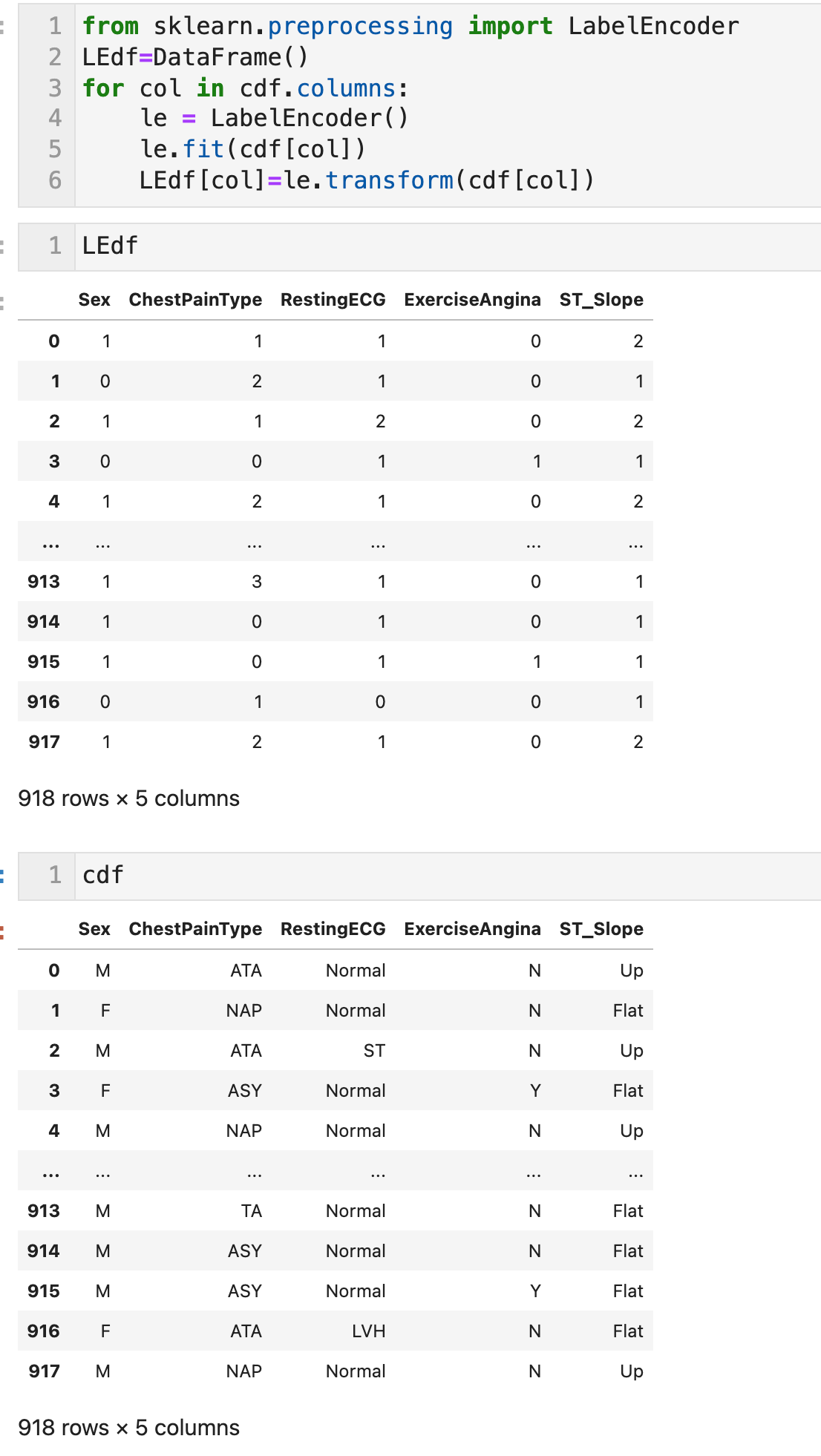
범주형 변수 변환 - 5) 레이블 인코딩 (Label encoding) with LabelEncoder
각 레벨을 단순히 정수로 변환하는 방법이다. Ordinal encoding이라고도 한다. 5개의 레벨이 있는 범주형 변수는 각 레벨이 0~4까지의 수치로 바뀐다.
사전 순으로 나열했을 때의 인덱스 수치는 대부분 본질적인 의미가 없다. 따라서 결정 트리 모델에 기반을 둔 방법이 아닐 경우 레이블 인코딩으로 변환한 특징을 학습에 직접 이용하는 건 그다지 적절하지 않다. 결정트리에서는 범주형 변수의 특정 레벨만 목적 변수에 영향을 줄 때도 분기를 반복함으로써 예측값에 반영할 수 있으므로 학습에 활용할 수 있다.
GBDT모델에서 레이벌 인코딩은 범주형 변수를 변환하는 기본적인 방법이다.
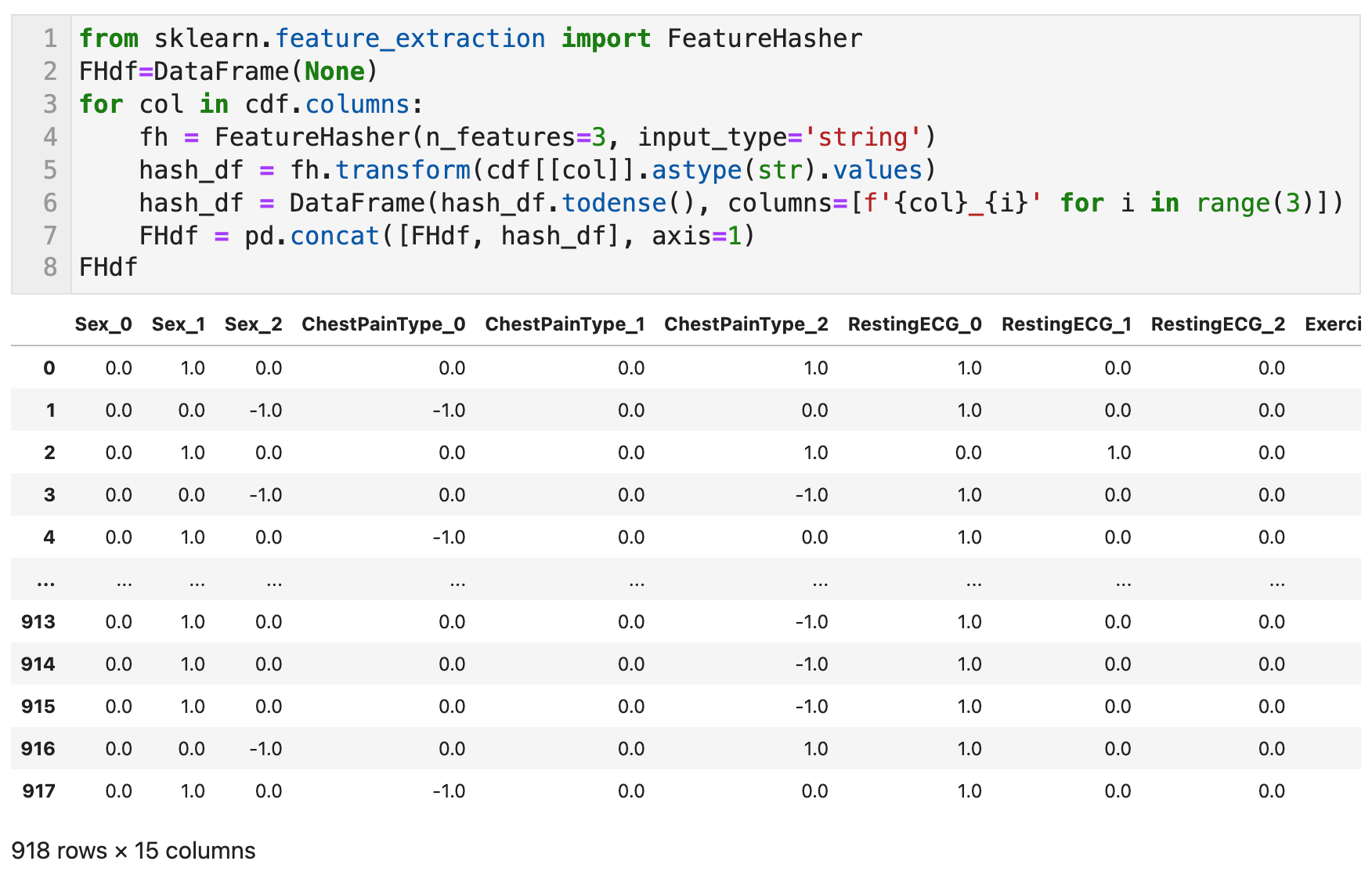
범주형 변수 변환 - 6) 특징 해싱 (Feature Hashing) with FeatureHasher
원핫인코딩으로 변환한 뒤 특징의 수는 범주의 레벨 수와 같아지는데 특징 해싱은 그 수를 줄이는 변환방법이다. 변환 후의 특징 수를 먼저 정해두고(파라미터 n_features) 해시 함수를 티용하여 레벨별로 플래그를 표시할 위치를 경정한다.
원핫인코딩에서는 레벨마다 서로 다른 위치에 플래그를 표시하지만 특징 해싱에서는 변환 후에 정해진 특징 수가 범주의 레벨 수보다 적으므로 해시 함수에 따른 계산에 의해 다른 레벨에서도 같은 위치에 플래그를 표시할 수 있다.
구현하기 쉽고, 모델 학습에 비용이 적게 들며, 새로운 범주 추가가 쉽고, 희귀 범주 처리가 쉽고, 온라인 학습이 가능한 장점을 가지고 있다. 반면, 선형 또는 커널 모델에만 적합하고 해시된 feature는 해석이 불가하며 정확도에 대해 엇갈린 보고가 있다.
Scikit Learn의 FeatureHasher 함수로 각 열을 대상으로
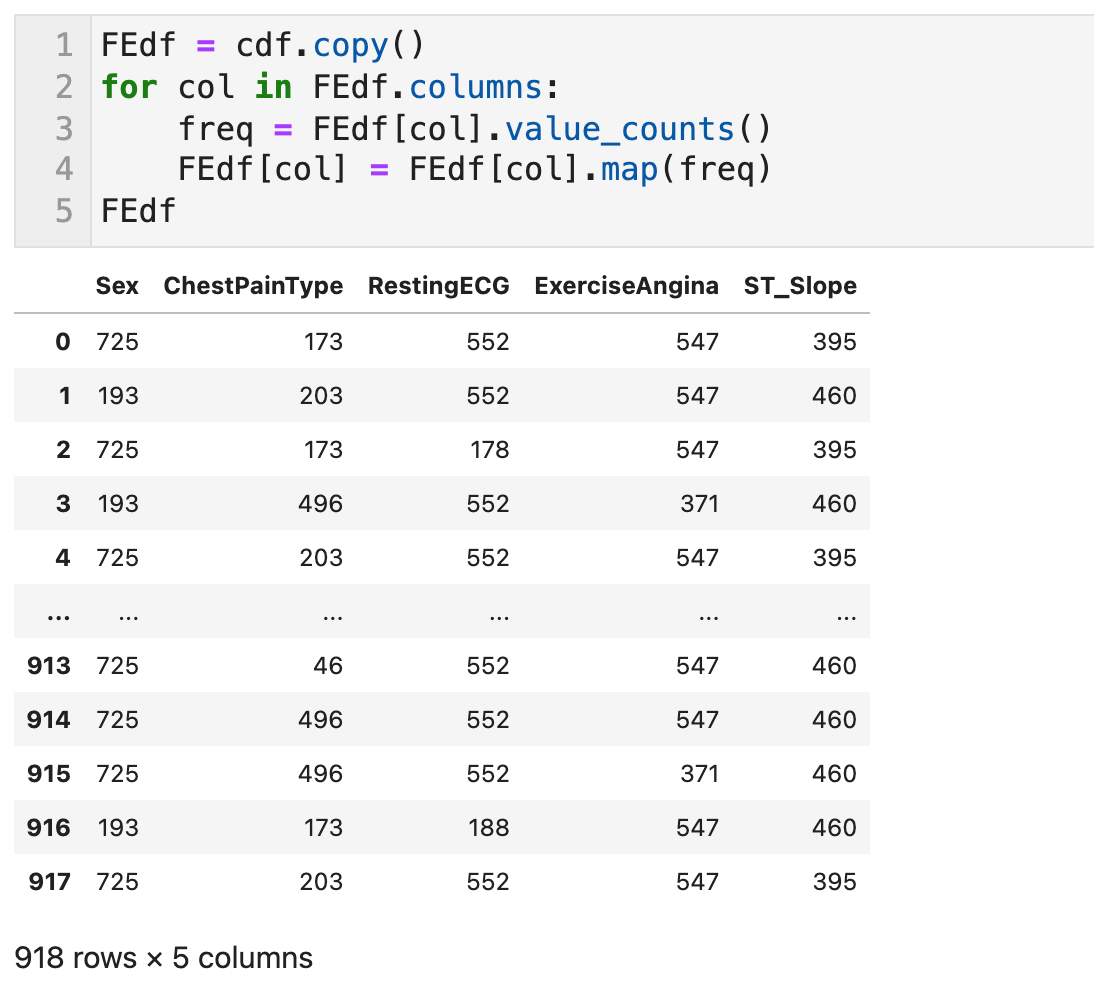
범주형 변수 변환 - 7) 빈도 인코딩 (Frequency Encoding) with value_counts, map
각 레벨의 출현 횟수 혹은 출현 빈도로 범주형 변수를 대체하는 방법이다. 각 레벨의 출현 빈도와 목적변수 간에 관련성이 있을 때 유효하다.
레이블 인코딩의 변형으로서 사전순으로 나열한 순서 인덱스가 아닌 출현 빈도순으로 나열하는 인덱스를 만들기 위해 사용할 수도 있다. 동률의 값이 발생할 수 있으니 주의해야 한다. 또한, 수치형 변수 스케일링과 마찬가지로 학습데이터와 테스트 데이터를 따로따로 정의하여 변환해버리면 다른 의미의 변수가 되므로 조심해야 한다.