ADP) ADP 실기 기출문제 모음 (17, 18, 19, 20, 21, 22, 23, 24, 25, 26회)
ADP 실기 문제집을 사기보다, 필기 문제집에 있는 각종 데이터마이닝 예제들을 직접 코드로 짜보는 것이 좋다는 후기들을 읽고, 코드 예제를 작성할 주제 목록을 잔뜩 만들었다. (정리하는데 꽤나 걸릴 것 같다 ^^;)
https://lovelydiary.tistory.com/380
ADP) ADP 실기 준비 - 주제 목록
내년 시행될 ADP 실기를 앞두고 아래와 같이 코딩 연습을 할 주제의 목차들을 정해보았다. 내용은 및 책을 기반으로 작성하였다. 가능한 한 빠뜨리는 내용 없이 모두 코드 작성을 해보려고 꼼꼼
lovelydiary.tistory.com
이외에도 어떻게 문제가 나왔었는지 알아야 할 것 같아서, 인터넷 서칭을 통해 여러 앞선 수험자분들이 복기해놓은 ADP 실기 기출문제들을 아래에 정리해보았다. 각 출처 링크를 통해 원글의 상세 내용을 확인할 수 있다.
ADP 17회 (출처: https://bigdata-analyst.tistory.com/34)
1. 머신러닝(data: Housing data - log1p로 정규화시킴)
- EDA, Preprocessing
- 모델링하고 예측
- 하이퍼파라미터 조절하여 오차 줄이기, 평가지표는 RMAE
2. 시계열분석 및 시각화(data: Covid19 - 일별 확진자수, 일별 완치자수로 데이터 가공 필요)
- 코로나 위험지수를 만들고, 그 위험지수에 대한 설명을 적고, 위험지수가 높은 국가들 10개를 선정해서 시각화
- 한국의 코로나 확진자 예측: 선형 시계열모델, 비선형시계열 모델 2개 만들기
3. 통계분석(data: 설문조사 - A~S까지의 그룹이 설문조사에 응답했고 중간에 반대 문항이 들어가 있음)
- 그룹별 통계치 계산
- 탐색적 요인분석을 표로 작성
ADP 18회 (출처: https://ysyblog.tistory.com/227)
1. 분류분석, 군집분석(SOM)
2. 텍스트마이닝: 문자열 전처리, 워드클라우드
3. 시계열: 정상성 체크 및 시계열 예측
4. 잔차 분석
ADP 19회 (출처: https://ysyblog.tistory.com/227)
1. 기계학습(data: credit 데이터 - 고객 이탈 여부 분류하는 문제, 독립변수는 성별, 나이, 카드등급, 소득 등)
- 데이터 전처리 및 시각화: 연속형 변수와 문자로된 범주형 변수 처리
- 훈련용 데이터와 검증용 데이터를 7:3으로 분할, 분류 분석 3개 실시, 혼동행렬 만들기
- 위의 분류 분석 3개를 앙상블하여 별도로 주어지는 credit test.cssv파일의 credit을 예측하고 result.csv로 제출
2. 통계분석(data: Traffic EPS 시계열 분석 - 매년 분기별로 작성된 20년치 데이터)
- 시계열 데이터의 정규성과 이분산성을 설명하기 위한 시각화
- 데이터가 정규성이 아니라면 고정 시계열이 있는지 확인하고 이를 처리
- SARIMA 분석을 통해 여러 파라미터를 적용해보고 가장 성능이 좋은 것을 제시
- 위 모델의 잔차와 잡음 시각화 및 분석
ADP 20회 (출처: https://ysyblog.tistory.com/227)
1. 시계열분석(data: 1년 간의 온도 데이터; 년월일, 실제온도, 지연값1, 지연값2, 친구의 예측값, 예측최소값, 예측값, 예측최대값 등 포함)
- 데이터 전처리: 필요없는 열처리, 데이터 전처리 증명, train/test set 나눌 방법 설명
- 랜덤포레스트로 검증 및 분석: 예측한계선 설정하는 방법 설명, 파라미터 조정을 통해 성능 강화, 컬럼별 중요도 시각화
- SVM으로 검증 및 분석: 예측한계선 설정하는 방법 설명, 파라미터 조정하여 성능 강화, 컬럼별 중요도 시각화
- 두 모델의 장단점 설명, 어느 모델이 더 좋은지 선택 및 설명, 선택한 모델의 한계점 및 해결방법
2. 군집분석(data: 가구별 15분 단위의 전력사용량; 년월일, 시간, 가구코드, 전력사용량 등 포함)
- 가구별, 15분 단위 전력 사용량의 합을 구하고, 이 데이터를 군집화하여 표 완성시키기 (가구코드, Date, 전력사용량의합, Cluster)
- 히트맵으로 시각화: 그룹별로 15분마다 전력 사용량을 요일별로 평균낸 것을 시각화
3. 회귀분석
- train/test 7:3 분할 및 검증 후 R2 score, RMSE, 정확도(공식 주어짐) 지표 계산
ADP 21회 (출처: https://cafe.naver.com/sqlpd/21090)
1. 머신러닝 (data: 학생 성적데이터: 독립변수 - school, sex, paid, activities, famrel, freetime, goout, dalc, walc, health, absences, 타겟변수 - grade)
- 시각화 포함 탐색적 자료분석
- 결측치 식별 및 결측치를 예측하는 방법 2가지 쓰고, 선택한 이유를 설명
- 범주형 변수 인코딩이 필요한 경우를 식별하고, 변환을 적용하고, 선택한 이유를 설명
- 데이터 분할 방법을 2가지 쓰고 적절한 데이터 분할을 적용. 선택한 이유를 설명
- svm, xgboost, randomforest 3개 알고리즘의 공통점을 쓰고, 예측 분석에 적합한 알고리즘인지 설명
- 3가지 방법으로 모두 모델링 해보고 가장 적합한 알고리즘 선택하고 이유 설명. 한계점 설명하고 보완 가능한 부분 설명. 현업에서 사용시 주의할 점 등에 대해 기술.
2. 머신러닝 (data: 연속형 독립변수 여러개의 소규모 데이터. 변수명은 순서대로 x1~x10 이라 의미 없음)
- 데이터 8:2로 분할하고 선형회귀 적용. 결정계수와 rmse 구하기.
- 데이터 8:2로 분할하고 릿지 회귀 적용. alpha 값을 0부터 1까지 0.1단위로 모두 탐색해서 결정계수가 가장 높을 때의 알파를 찾고, 해당 알파로 다시 모델을 학습해서 결정계수와 rmse를 계산
- 데이터 8:2로 분할하고 라쏘 회귀 적용. alpha 값을 0부터 1까지 0.1단위로 모두 탐색해서 결정계수가 가장 높을 때의 알파를 찾고, 해당 알파로 다시 모델을 학습해서 결정계수와 rmse를 계산
3. 시각화 (data: 독립변수 하나 종속변수 하나 소규모 데이터)
- 다항 회귀를 3차까지 적용하고 각 차수별 스캐터 플롯과 계수와 회귀선 그리기
4. 통계분석:
- 이원분산분석을 수행하고 통계표 작성
- 변수 3개(하나는 abcde 각각을 값으로 갖는 범주형 변수, 나머지 두 개는 수치형 연속변수)
ADP 22회 (출처: https://ysjang0926.github.io/data/2021/09/22/ADP-22-comments/)
1. 머신러닝 (data: Pima Indian Diabetes)
- 탐색적 데이터 분석: 결측치 확인, 히스토그램/박스플롯/페어플롯, 타겟변수 분포 그래프의 불균형 확인, 변수 전체의 상관관계, 이상치 처리 방안 제시, 위의 전처리 단계에서 얻은 향수 분석 시 고려사항 작성
- 클래스 불균형 처리: 오버샘플링, 언더샘플링 과정 설명하고 결과 작성, 둘 중 선택하고 그 이유 설명
- 모델링: 최소 3개 이상 알고리즘 제시하고 정확도 측면의 모델 1개와 속도 측면의 모델 1개를 구현, 모델 비교하고 결과 설명, 속도 개선을 위한 차원 축소 설명하고 수행, 성능과 속도 비교하여 결과 작성
2. 통계분석 (data: 금속 성분 함유량 데이터)
- 제품에 금속 재질 함유량의 분산이 1.3을 넘으면 불량이라고 보는데 제조사별로 차이가 남. 분산 검정 수행. 유의확률 0.05
- 불량률 관리도에 따른 관리 중심선, 관리 상한선, 하한선 구하기 (각 공식 있음), 관리도 시각화
3. 데이터 없음
- 표에 제품 1, 2를 만드는데 재료 a, b, c가 사용됨. 제품 1, 2는 각각 12만원, 18만원. 재료는 한정적일 때 최대 수익을 낼 수 있을 제품 1과 제품2의 개수 구하기
4. 데이터 없음
- 상품 a와 b가 있을 때 구매 패턴이 aa bb aaaa bbbb a b 등으로 나타날 때 두 상품의 연관성 유무를 검정할 것
ADP 23회 (출처: https://cafe.naver.com/sqlpd/28193)
1. 머신러닝 (data: 객실 사용 여부 관련 데이터, 독립변수는 온두, 습도, CO2, 빛, 총 290개 가량의 관측치)
- 분류문제, class 불균형 데이터로 0이 12%, 1이 88%로 구성
- 데이터 탐색하고 탐색 결과 제시
- 결측치 탐색하고 대체 방법 및 근거 제시
- 추가적으로 데이터 질을 향상시킬만한 내용 작성 (구현 없이 설명만해도 됨)
- 데이터 불균형을 시각화하여 식별하고 불균형 판단근거 작성
- 오버샘플링 기법 설명하고 비교한 뒤 2개 기법 선정 및 근거제시
- 선정한 이유 작성하고, 원데이터 포함 3개 데이터 세트 구성
- 오버샘플링 데이터와 원데이터 사용하여 정확도 측면 모델 하나 속도 측면 모델 하나 선정
- 선정한 이유 작성
- 원 데이터와 오버샘플링 데이터를 가지고 각각 분류하여 오버샘플링이 성능에 미친 영향에 대해 작성
2. 통계분석
- 공장에서는 진공관 수명이 1만 시간이라고 주장하여 품질관리팀에서 12개 샘플을 뽑았음 유의수준 5%에서 부호 검정하시오
- 1. 연구가설 귀무가설 작성(5)
- 2. 유효한 샘플의 수를 계산(5)
- 3. 검정통계량 및 연구가설 채택 여부 작성(5)
- 코로나 시계열 데이터 5만 관측치 가량, 날짜, 코로나 누적확진자 등 변수 3개
- 1. ACF 사용해서 distance 계산 (10)
- 2 계층적 군집 분석을 위해 덴드로그램 작성 (10)
- 사회과학 자연과학 공학 세개 학과의 평점 조사표: 3.5-4.5, 2.5-3.5, 1.5-2.5 3개 점수구간이 row index이며 학과가 컬럼이고 값으로는 사람 수가 들어가있음. 학과와 성적이 관계있는지 검정하시오
- 연구가설 귀무가설 작성(5)
- 학과와 성적이 독립일 때 기댓값 구하시오(5)
- 검정통계량 구하고 연구가설 채택여부 작성(5)
ADP 24회 (직접 작성)
1. 머신러닝 (data: 학생 결석일수 관련 데이터, 독립변수 12개 - 성별, 나이, 부모와 같이 사는지 여부, 아버지 학력, 어머니 학력, 보호자, 집학교 거리, 공부 시간, F학점 맞은 횟수, 가족 관계, 여가시간, 총 395개의 관측치) -50점
- 시각화 포함하여 탐색적 분석하기
- 시각화 포함하여 전처리 하기
- 이밖에 추가할 수 있는 전처리를 하고, 그 이유와 기대효과를 쓰기
- 해당 데이터셋에서 학생결석 일수를 예측하는데에 적용 가능한 알고리즘 3개를 언급하고 그 중 2개를 선택하고, 그 이유를 설명하기
- 해당 모델에 성능 평가 지표를 뭘로 쓸건지 그 이유를 설명하기
- 선정한 2개 알고리즘으로 실제 코딩한 후 성능 평가를 통해 비교하고 설명하기 (시각화 포함)
- 실제로 사용가능한 모델인지 설명
- 다양한 환경에서 적용할 수 있는 방안 설명
- 추가적으로 모델 개선할 수 있는 방안 설명
2. 통계분석 - 50점
- 광고비(범주형 변수, 높음과 낮음으로 적혀있음), 연구개발비(수치형 변수, 수치 적혀있음), 판매액(수치형 변수, 수치 적혀있음), 전체 관측치는 10개로 소규모 데이터. 광고비와 연구개발비가 독립변수, 판매액이 종속변수.
- 광고비를 가변수화해서 다중선형회귀방정식을 만들고 회귀계수를 검정하기
- 회귀 모형을 검정하기
- A생산라인의 제품 평균은 5.7mm이고 표준편차는 0.03, B생산라인의 제품 평균은 5.6mm이고 표준편차는 0.04라면 5%유의수준으로 두 제품의 평균이 차이가 있는지 여부를 검정하기 (Z통계량도 제공 - Z(0.05) = 1.65, 위의 구체적인 숫자는 실제 시험 때 숫자랑 정확하게 맞지는 않음)
- 귀무가설과 대립가설 세우기
- 두 평균이 차이가 있는지 검정 하기
- 베이지안 분류 문제 - 바이러스 감염 분류표를 보고 베이지안 분류 방법을 사용해 양성으로 예측된 사람이 실제로 양성일 확률을 구하는 문제
- 수치는 실제 시험과 다를 수 있음

- 9개 정도의 숫자 표본에 대해 단일표본 T검증을 진행하여 아래 내용을 구하기
- 위 표본의 평균에 대한 신뢰구간 구하기
- 과거에 해당 표본의 모집단의 표준편차가 0.4일 때 표본 평균에 대한 신뢰구간 구하기
ADP 25회 (직접 작성)
머신러닝 (50점)
1. 군집분석
- 각 5점씩 총 20점
- InvoiceNo, CustomerID, Date, UnitPrice, Quantity 등 feature로 구성된 대용량 데이터셋
1-1. F(소비자별 구매빈도), M(소비자별 총 구매액) feature를 새로 생성해서 그 결과값으로 탐색적 분석 실시
1-2. F, M feature 기반으로 군집분석 실시, 필요시 이상값 보정
1-3. 군집 결과의 적합성을 군집 내 응집도, 군집 간 분리도의 개념을 사용해서 서술
1-4. 적합된 군집 별 특성에 대한 의견과 비즈니스적 판단 제시
2. 시계열분석
- 5, 5, 15, 5점씩 총 30점
- 유입관광객 수와 인덱스 번호만으로 구성된 200여개의 데이터셋
2-1. 탐색적 분석
2-2. 결측치가 있을 경우, 적절한 처리할 것
2-3. 계절성 있는 시계열 모델을 적합하기
2-4. 해당 시계열 모델을 평가하기
통계분석 (50점) ** 문제의 숫자들은 임의로 입력했기 때문에 실제 시험과 다를 수 있음
3. 여러 통계 문제
- 각 5점씩 총 20점
3-2. 연매출이 3000, 4000, 5000이었다면 연평균 몇배가 증가한 것인가? (기하평균)
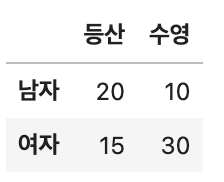
3-3. 남성, 여성의 등산, 수영에 대한 취미 선호도 빈도표(2x2)를 보고, 남성 중에서 등산을 좋아할 확률을 구하시오
3-4. 표본 10개의 분산이 90일 때 신뢰도 95%로 모분산의 신뢰구간을 추정
- 각 5점 씩 총 10점
- 혈압약을 복용하기 전과 후의 혈압 표본 20개를 제시할 때, 혈압약 복용 후 혈압이 더 낮아졌을 거라고 예상한다.
- 각 5점 씩 총 10점
- X, Y, Z 공장의 생산량 데이터와 전체 순위 데이터가 10개씩 주어짐
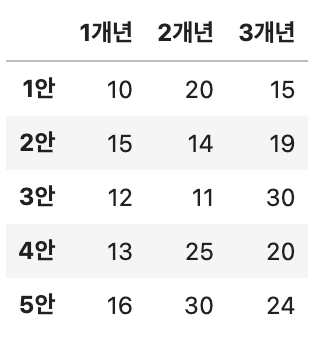
6. NPV 문제
- 10점
- 1개년 50억, 2개년 60억, 3개년 70억의 예산을 가지고 NPV(순현재가치)가 가장 높아지는 안을 제시하시오.
ADP 26회 (직접 작성)
머신러닝 (50점)
1 & 2. 군집분석
- 데이터: CustomerID, StockCode, StockCategory, Quantity, UnitPrice, Country 등 feature로 구성된 구매 데이터, 범주형과 수치형 데이터가 혼합되어 있고 Quantity에 결측치가 있었음
1-1. 결측치를 확인하고, 결측치 제거할 것
1-2. 이상치 제거하는 방법을 설명하고, 이상치 제거하고 난 결과를 통계적으로 나타낼 것
1-3. 전처리한 데이터로 Kmeans, DBSCAN 등 방법으로 군집을 생성할 것
2-1. 위에서 생성한 군집들의 특성을 분석할 것
2-2. 각 군집 별 대표추천 상품을 도출할 것
2-3. CustomerID가 12413인 고객을 대상으로 상품을 추천할 것
통계분석 (50점)
3. 불량률이 0.9인 경우, 오차의 한계가 5%가 되도록하는 최소 표본 사이즈는?4. 지역별 특정 후보에 대한 지지율 차이가 있는지 여부에 대한 검정 문제A, B, C 지역에서 지지하는 사람 수가 각각 100, 200, 300 (숫자는 기억이 안나서 임의로 입력함)
A, B, C 지역에서 지지하지 않는 사람수가 각각 150, 130, 180 (임의의 숫자임)
4-1. 지역별 지지율 차이에 대한 연구가설과 귀무가설 설정하기
4-2. 검정통계량을 구하고 가설 판단하기
5. 남녀 학생들의 평균 혈압 차이가 있는지 여부에 대한 검정 문제
남학생의 혈압 데이터 16개, 여학생의 혈압 데이터 9개가 주어짐 (정확한 개수와 데이터 값은 기억이 안나서 임의로 입력함)
남 = [103, 100, 98, 101, ...] 여 = [100, 101, 109, ...]
5-1. 남녀 학생들의 평균 혈압 차이가 있는지에 대해 연구가설과 귀무가설 설정하기.
5-2. 검정통계량을 구하고 판단하기.
5-3. 평균 혈압차의 신뢰구간을 구했을 때 판단한 결과가 5-2의 결과를 지지하는지 설명하기.
6. 은 가격 1~9월 시계열 데이터
6-1. 은가격과 3 window의 롤링평균 한 그래프에 플롯팅하기
6-2. 1월 대비 9월에 은 가격이 몇 퍼센트 증가하였는지 계산하기
7. Weight, Height, Waist로 이루어진 수치형 데이터
7-1. 베이지안 회귀를 통해 회귀계수 계산하기. 베이지안 회귀를 위한 각종 파라미터가 제시됨.
7-2. 몸무게가 80이고, 키가 170일 때 허리둘레를 예측하시오. (숫자는 임의로 입력함)
[ADP 실기 기출문제 풀이]
https://lovelydiary.tistory.com/453
ADP 기출문제 풀이) 탐색적 분석 관련 문제들 w/Python
예전부터 기출문제 풀이 관련 포스팅을 해보려고 생각만 하고 있었는데, 드디어 ADP 실기 기출문제에 대한 포스팅을 시작해본다. ADP와 빅분기를 준비하는 분들이 많이 사용하고 있는 데이터마님
lovelydiary.tistory.com
[ADP 실기 대비 추천 도서]
ADP 실기 책 추천) 핵심만 요약한 통계와 머신러닝 파이썬 코드북
ADsP와 ADP 필기의 산을 넘어 ADP 실기 준비의 길로 접어들면, 방대한 공부 분량에 정신이 아찔해진다. ^^; 그래서 많은 분들이 다양한 통계책, 머신러닝 책을 참고하며 스스로의 코드북을 만든다. AD
lovelydiary.tistory.com