ADP 실기 기출문제 풀이 세번째 포스팅의 내용은 베이지안 회귀와 2차 교호작용항을 고려한 다중선형회귀 문제이다. 대부분의 회귀 문제는 오차제곱합을 최소화하는 방식으로 회귀식을 찾아갔는데, 베이지안 회귀 문제가 나와서 '이런 것도 있어?' 하고 당황했던 기억이 난다. 통계와 머신러닝은 공부할 수록 모르는 것이 화수분처럼 나오는 그런 학문이다^^
여튼, 이번 포스팅에서는 ADP 실기 17회와 26회에서 나왔던 문제들을 풀어보았다. 만점짜리 풀이는 아니기 때문에 참고로 해주시길 바라며...
4. 부동산 가격 예측 데이터 (ADP 실기 17회)
Id: id
LotArea: Lot size in square feet
LotFrontage: Linear feet of street connected to property
YearBuilt: Original construction date
1stFlrSF: First Floor square feet
2ndFlrSF: Second floor square feet
YearRemodAdd: Remodel date
TotRmsAbvGrd: Total rooms above grade (does not include bathrooms)
KitchenAbvGr: Number of kitchens
BedroomAbvGr: Number of bedrooms above basement level
GarageCars: Size of garage in car capacity
GarageArea: Size of garage in square feet
price: the property's sale price in dollars. This is the target variable that you're trying to predict.
[출처] https://www.datamanim.com/dataset/ADPpb/00/17.html

# 4-3. 2차 교호작용항까지 고려한 회귀분석을 수행하고, 변수 선택 과정을 제시하시오.
해당 문제를 풀기 전 앞선 포스팅에서 탐색적 데이터 분석 및 전처리(https://lovelydiary.tistory.com/454)를 진행하였다. 전처리한 데이터를 이어서 해당 문제를 풀어본다.
먼저 원본 데이터에서 수치형 변수에 2차항을 추가한 후, 변수를 선택하는 방법을 진행하였다. 변수 선택 방법으로는 VIF를 통해 다중공선성이 있는 변수를 제거하는 방법과, AIC, BIC를 최소로 하는 변수의 조합을 찾는 단계적 방법과, Mallows Cp를 계산하여 설명변수의 개수와 비교하여 가장 비슷한 모델을 선택하는 방법 등이 있다. 여기서는 VIF를 통해 다중공선성을 확인한 후 일부 변수를 제거하고, AIC를 최소로 하는 변수의 조합을 찾는 단계적 방법을 실시하였다.


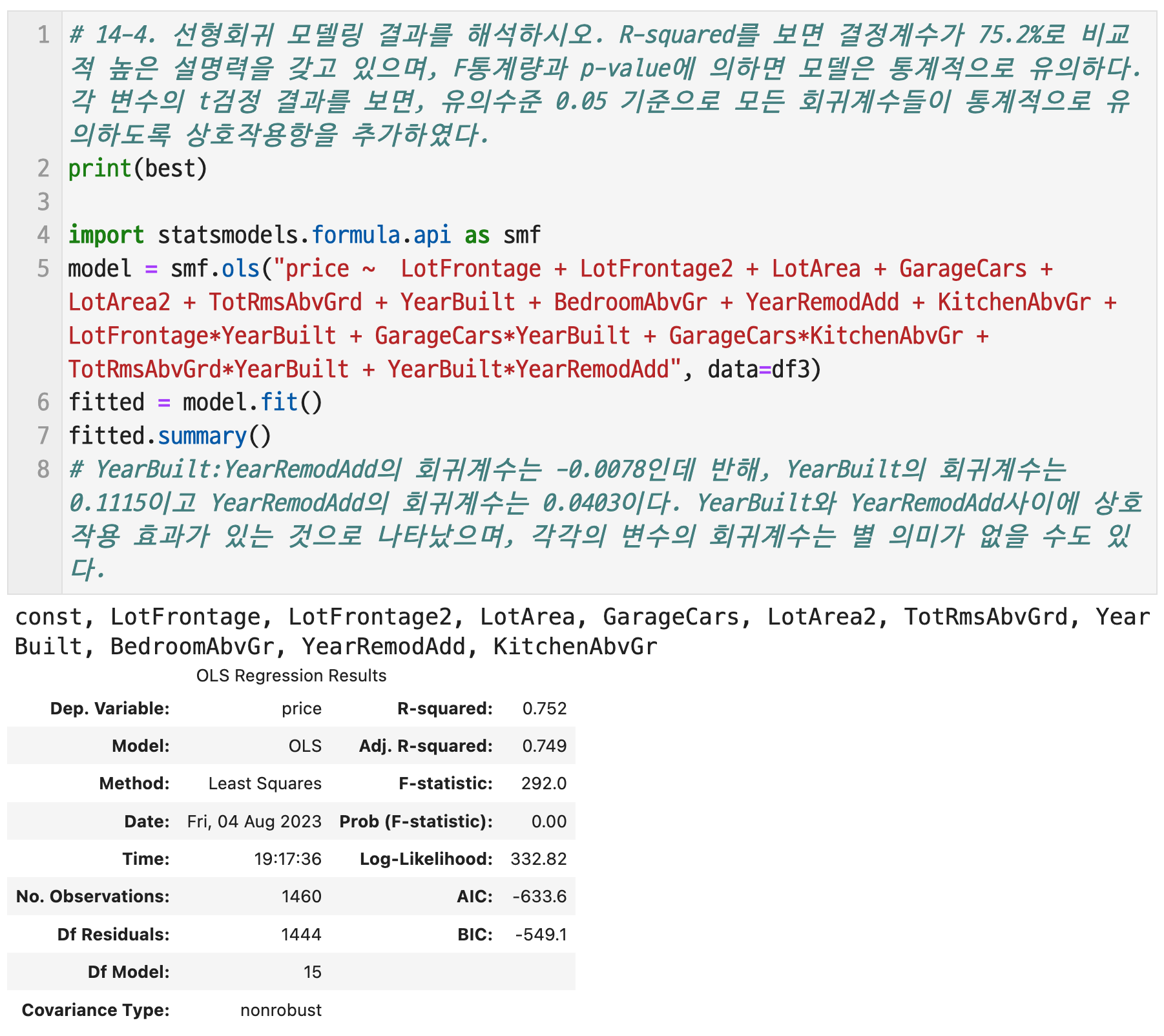
# 4-4. 선형회귀 모델링 결과를 해석하시오
R-squared를 보면 결정계수가 75.2%로 비교적 높은 설명력을 갖고 있으며, F통계량과 p-value에 의하면 모델은 통계적으로 유의하다. 각 변수의 t검정 결과를 보면, 유의수준 0.05 기준으로 모든 회귀계수들이 통계적으로 유의하도록 상호작용항을 추가하였다.
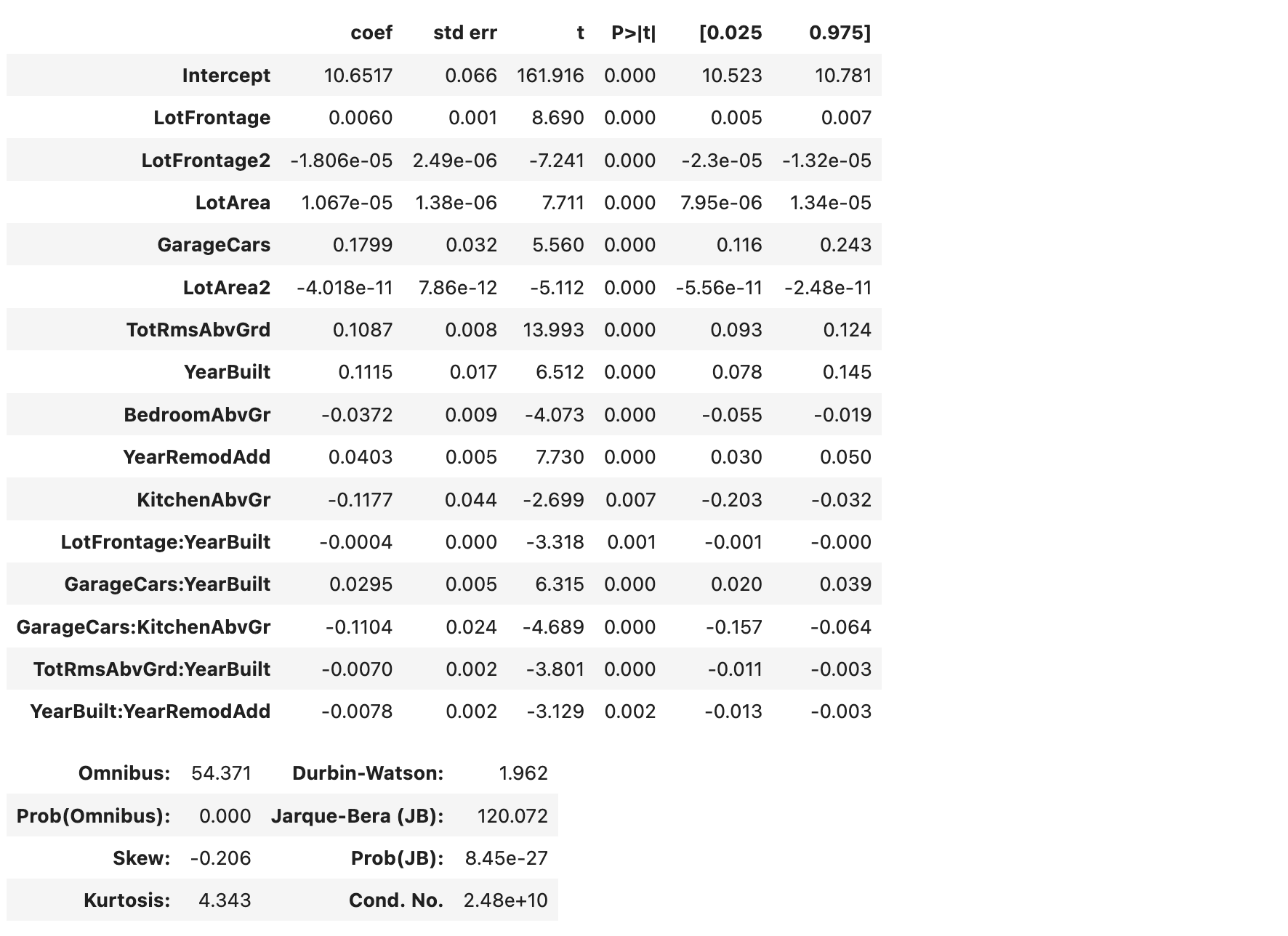
YearBuilt:YearRemodAdd의 회귀계수는 -0.0078인데 반해, YearBuilt의 회귀계수는 0.1115이고 YearRemodAdd의 회귀계수는 0.0403이다. YearBuilt와 YearRemodAdd사이에 상호작용 효과가 있는 것으로 나타났으며, 각각의 변수의 회귀계수는 별 의미가 없을 수도 있다.
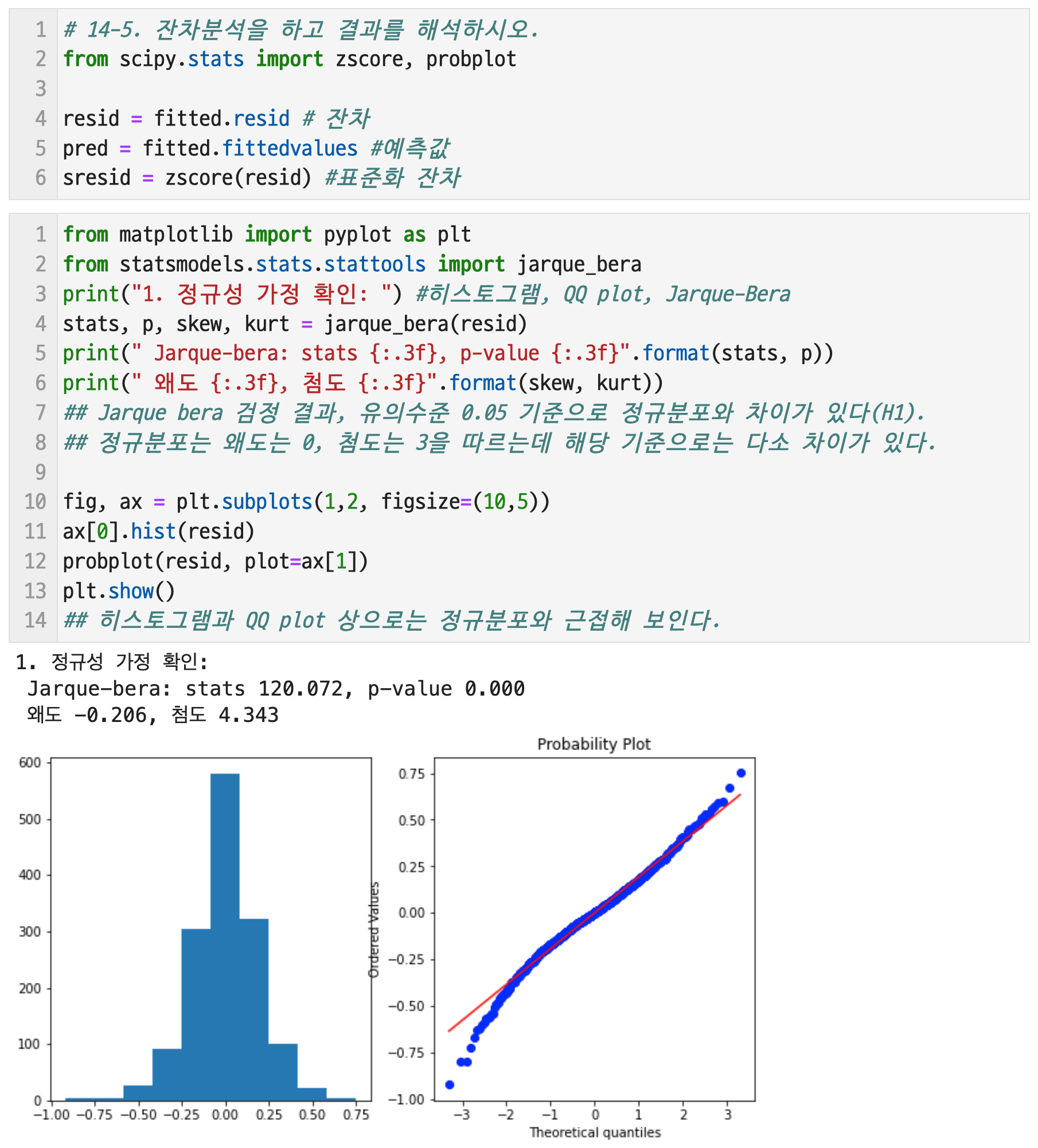
# 4-5. 잔차분석을 하고 결과를 해석하시오.
잔차의 정규성을 살펴보면, Jarque bera 검정 결과 유의수준 0.05 기준으로 정규분포와 차이가 있다(H1). 정규분포는 왜도는 0, 첨도는 3을 따르는데 해당 기준으로는 다소 차이가 있다. 히스토그램과 QQ plot 상으로는 정규분포와 근접해 보인다. 정규성을 만족한다고 보기는 힘들어 보인다.
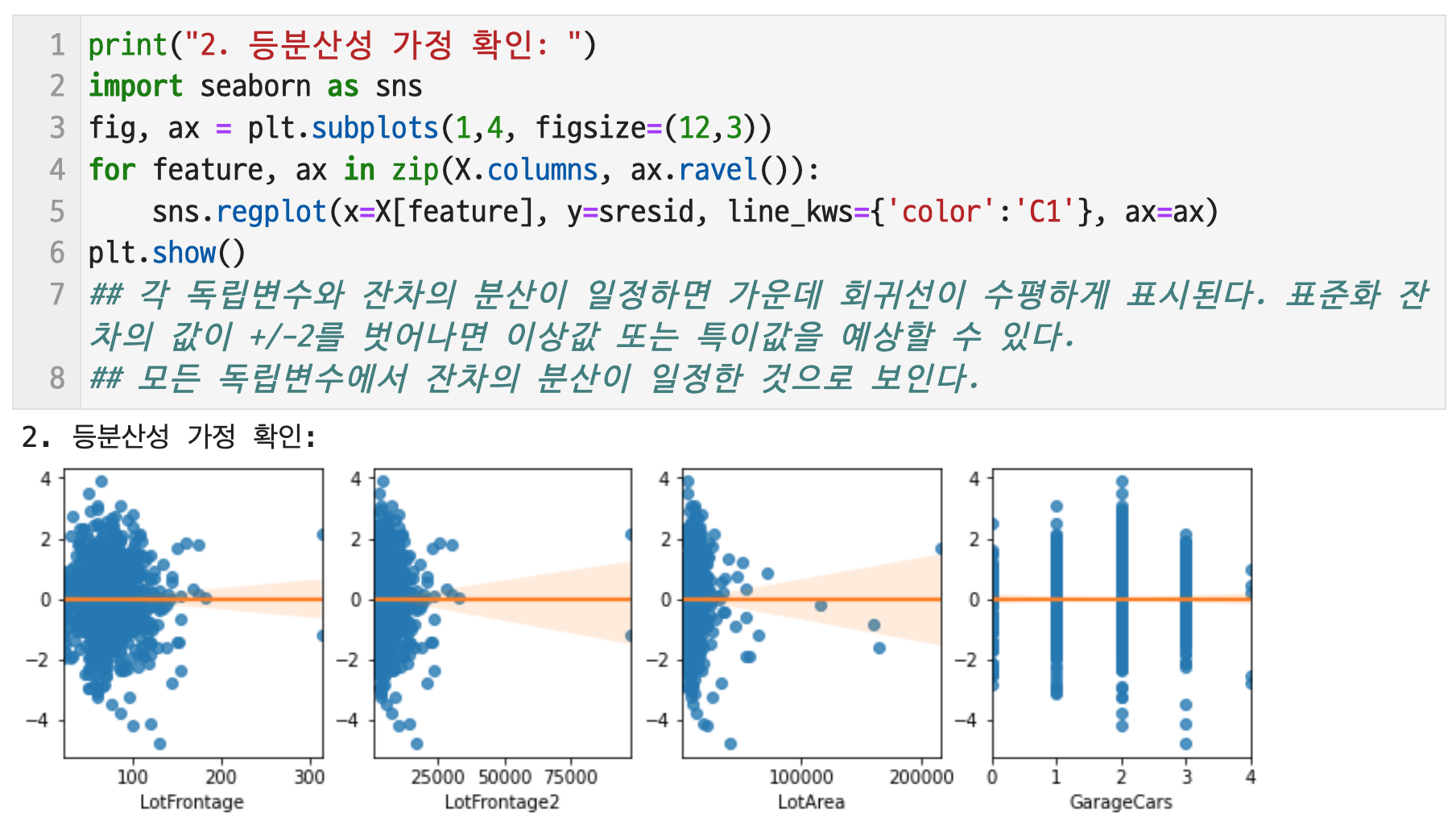
잔차의 등분산성을 살펴보면, 각 독립변수와 잔차의 분산이 일정하면 가운데 회귀선이 수평하게 표시된다. 표준화 잔차의 값이 +/-2를 벗어나면 이상값 또는 특이값을 예상할 수 있다. 모든 독립변수에서 잔차의 분산이 일정한 것으로 보인다.
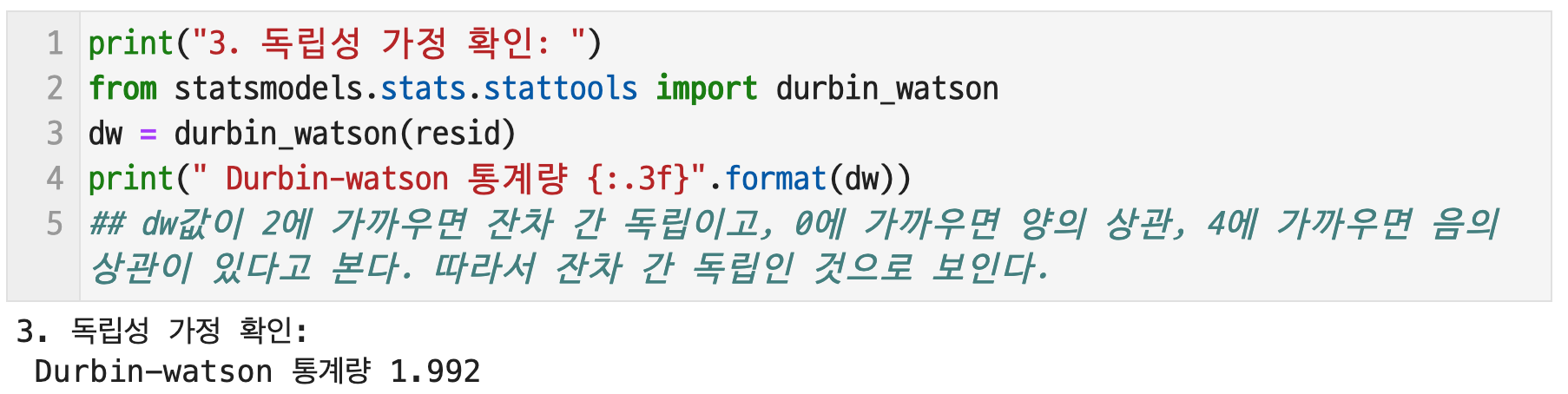
잔차의 독립성을 살펴보면, dw값이 2에 가까우면 잔차 간 독립이고, 0에 가까우면 양의 상관, 4에 가까우면 음의 상관이 있다고 본다. 따라서 잔차 간 독립인 것으로 보인다.
잔차의 가정들을 만족하지 못하는 경우, 해당 회귀 모델의 결과를 신뢰하기 어려우므로 추가적인 데이터 보완이나 전처리를 통해 잔차의 가정을 만족하도록 회귀 모델을 다시 만들어야 한다.
5. 체중 예측 데이터 (ADP 실기 26회)
features: height, waist
target: weight
[출처] https://www.datamanim.com/dataset/ADPpb/00/26.html
# 5-1. 아래 조건을 참고하여 회귀계수(반올림하여 소수점 두자리)를 구하시오.
- 베이지안 회귀
- 시드넘버 1234로 지정
- 1000번의 burn-in 이후 10,000의 MCMC를 수행
- 회귀계수의 사전분포는 부적절한 균일분포(improper uniform prior distribution), 오차항의 분산의 사전분포는 역감마 분포로 지정. 이때, 형상(Shape)모수와 척도(Scale)모수는 각각 0.005로 지정.
마르코프 체인은 어떤 상태가 바로 전 상태에 의존하는 경우를 말하고, 몬테카를로는 무작위 샘플링을 하는 것을 의미한다. MCMC(Markov Chain Monte Carlo)는 마코프 체인을 이용해 표본을 생성하는 방법이고, 그 방법들에는 Metropolis-Hastings Sampling, Hamiltonian Monte Carlo, NUTS(No-U-Turn Sampler) 등이 있다. 여기에서는 jax, numpyro 라이브러리를 활용하여 NUTS 방법으로 회귀 모델링을 진행한다.


# 5-2. 위에서 만든 모델을 바탕으로 키 180cm, 허리둘레 85cm인 남성의 몸무게를 추정하라.

'Study history > ADP 기출문제 풀이' 카테고리의 다른 글
| ADP 기출문제 풀이) 구매 데이터 군집분석 문제 w/Python (2) | 2023.08.30 |
|---|---|
| ADP 기출문제 풀이) 추정과 가설검정 문제들 w/Python (0) | 2023.08.29 |
| ADP 기출문제 풀이) 대구 임대 아파트 데이터 분석 문제 w/Python (0) | 2023.08.28 |
| ADP 기출문제 풀이) 데이터 전처리 관련 문제들 w/Python (0) | 2023.08.24 |
| ADP 기출문제 풀이) 탐색적 분석 관련 문제들 w/Python (0) | 2023.08.23 |




댓글