#1. 이원분산분석이란 무엇일까?
종속변수가 1개, 독립변수가 2개이면서 독립변수 각각이 factor(요인)로서 factor내에 level(수준)을 가지고 있을 때,
각 집단의 평균의 유의미한 차이가 있는지 유무를 확인하기 위해 Two way Anova(ANalysis Of Variance) 즉, 이원분산분석을 진행한다.
factor1 (level 1, 2, 3) + factor2 (level a, b)의 조합일 경우, 비교해야 하는 경우의 수는 아래와 같다.
-----------------------------------------------------------------------------------------
factor1 내에서 3C2=3개 (1-2, 1-3, 2-3)
factor2 내에서 2C2=1개 (a-b)
factor1과 2의 수준들을 짝짓고 비교해야 하는 경우의 수는 (level 1, 2, 3; 3개 * level a, b; 2개 = 6개) 그리고 이 쌍들 중에서 순서없이 2개씩 고르는 경우의 수 6C2=15개
-----------------------------------------------------------------------------------------
이렇게 총 19번을 두 집단을 비교해야 하니 수기로 한다면 쉽지 않은 작업이다.
그래서 일단은 factor내에서 집단 간 평균 차이가 유의미한지를 확인하기 위해 Anova table로 각 factor별, factor:factor 간의 F통계량과 그에 따른 P값을 확인한다. 그리고나서 P값이 유의수준 0.05보다 작은 경우에 그 집단 내 적어도 한 그룹은 평균이 유의미하게 차이가 있을 것이라고 판단하고 해당 case의 경우만 추출하여 사후 분석을 추가로 진행한다. 구체적으로 어떤 집단에서 유의미한 평균 차이를 보이는지 확인해야 하기 때문이다.
#2. 파이썬과 R로 이원분산분석 실습하기 (아노바 테이블 출력하기):
하나의 독립변수 내의 수준 간에 유의미한 평균 차이가 날 경우, 주효과 (Main effect)가 있다고 하고,
독립변수1의 수준과 독립변수2의 수준 간에 유의미한 평균 차이가 날 경우, 교호작용(interection effect)이 있다고 한다.
파이썬과 R로 이원분산분석을 각각 진행해보았다. 역시나 아노바 테이블 결과값을 비교하니,
두 언어 모두 동일한 값의 아노바 테이블을 결과로 제시했다.
[파이썬]
먼저 pandas, statsmodels 패키지에서 필요한 메서드들을 불러온다.
|
1
2
3
|
from pandas import DataFrame
from statsmodels.formula.api import ols from statsmodels.stats.anova import anova_lm
from statsmodels.stats.multicomp import pairwise_tukeyhsd
|
cs |
불러온 DataFrame으로 데이터 프레임을 만든 후,
statsmodel의 anova_lm과 ols 메서드로 간단하게 아노바 테이블 결과값을 확인할 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
|
df9=DataFrame({'판유리':['유리1', '유리1', '유리1', '유리2', '유리2', '유리2', '유리3', '유리3',
'유리3', '유리1', '유리1', '유리1', '유리2', '유리2', '유리2', '유리3', '유리3', '유리3', '유리1',
'유리1', '유리1', '유리2', '유리2', '유리2', '유리3', '유리3', '유리3'], '온도':[100, 100, 100,
100, 100, 100, 100, 100, 100, 125, 125, 125, 125, 125, 125, 125, 125, 125, 150, 150, 150,
150, 150, 150, 150, 150, 150], '강도':[580, 568, 570, 550, 530, 579, 546, 575, 599, 1090,
1087, 1085, 1070, 1035, 1000, 1045, 1053, 1066, 1392, 1380, 1386, 1328, 1312, 1299, 867, 904, 889]})
anova_lm(ols('강도~판유리*온도', df9).fit())
|
cs |
[R]
먼저 각 열을 하나의 벡터(열이름<-c(....))로 각각 만들고 data.frame함수를 통해 데이터 프레임을 만든다.
이 중, 독립변수 열들은 transform함수를 통해 factor()로 정의해서 해당 내용을 다시 데이터 프레임에 적용시킨다.
그리고나서 summary(아노바<-aov(종속변수~독립변수1*독립변수2, data=데이터프레임 이름))을 입력하면 아노바 테이블 분석 결과를 확인할 수 있다.
[파이썬과 R의 아노바 테이블 비교]
파이썬과 R 모두 동일한 값을 가진 아노바 테이블을 출력하는 것을 확인할 수 있다.
결과값에 따르면 강도-판유리, 강도-온도, 강도-판유리:온도의 세 경우 모두에서 유의미한 P(p-value)값이 나왔기 때문에(유의수준 p < 0.05) 세 경우 모두 사후분석을 통해 집단 간 유의미한 평균 차이가 있는지 비교해야 한다.
하지만 꼭 다하지 않고 그중에 P값가 가장 작은 하나만 진행하기도 한다고 한다.

#3. 파이썬과 R로 TukeyHSD 사후분석 진행:
여러가지 사후분석 방법이 있지만 그 중에서도 TukeyHSD 사후분석 방법으로 실습을 해보았다.
파이썬은 statsmodel과 bioinfokit 두 가지 패키지를 사용해서 사후분석을 진행했다.
[파이썬 1: statsmodel]
statsmodel로 tukeyHSD 사후분석을 진행하기 위해서는 combi라는 열을 만들어야 한다. 열이름이야 임의로 지어도 무관하지만, 독립변수1과 2과 서로 짝을 짓는 모든 경우의 수와 종속변수값을 matching해 주어야 statsmodel을 이용한 사후분석을 진행할 수 있다.
|
1
2
3
|
df9['온도']=df9['온도'].astype('str')
df9['combi']=df9.판유리 + " / " + df9.온도
print(pairwise_tukeyhsd(df9['강도'], df9['combi']))
|
cs |
combi열을 생성하고 나면 df9는 아래와 같이 내용이 변경된다.
참고로 온도열과 같이 숫자값으로 데이터값을 가지는 경우에는 combi열을 만들기 전에 string으로 먼저 데이터 타입 변경을 해주어야 한다. 안 그러면 에러가 난다.

그 후에 위의 코드와 같이 pairwise_tukeyhsd(종속변수열, 콤비열)함수를 실행하면 다음과 같은 사후분석 결과를 확인할 수 있다. FWER 0.05, 즉 유의수준 0.05 하에서 유의미한 p값을 가지는 케이스들은 reject에 True로 표기가 된다. 해당 케이스들은 집단 수준 간 유의미한 평균 차이를 보인다고 볼 수 있다.
[파이썬 2: bioinfokit]
이원분산분석의 사후분석을 하는 또다른 파이썬 패키지로 bioninfokit가 있다.
코드는 아래와 같다.
|
1
2
3
4
5
6
7
|
from bioinfokit.analys import stat
res=stat()
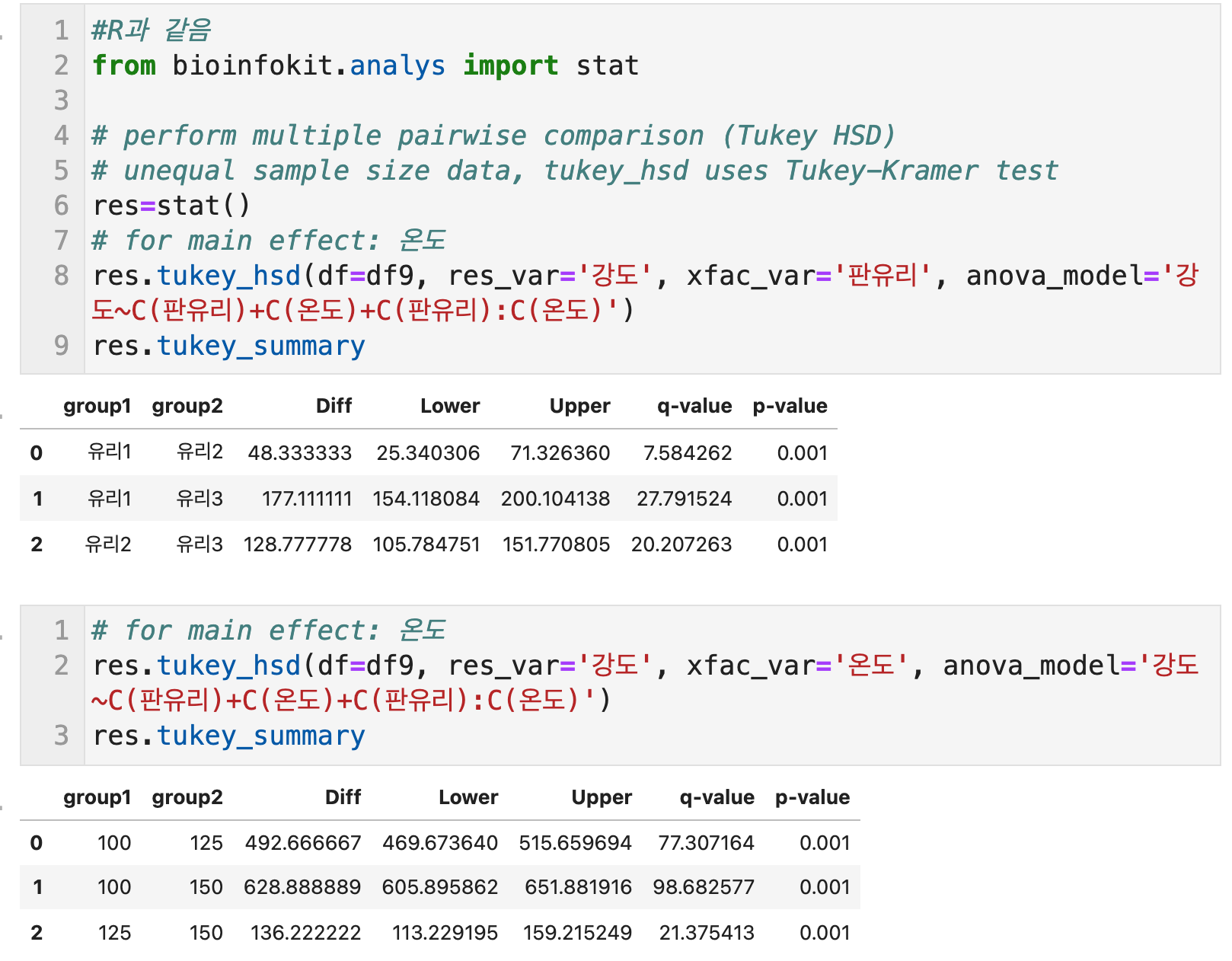
# for main effect: 판유리
res.tukey_hsd(df=df9, res_var='강도', xfac_var='판유리',
anova_model='강도~C(판유리)+C(온도)+C(판유리):C(온도)')
res.tukey_summary
|
cs |
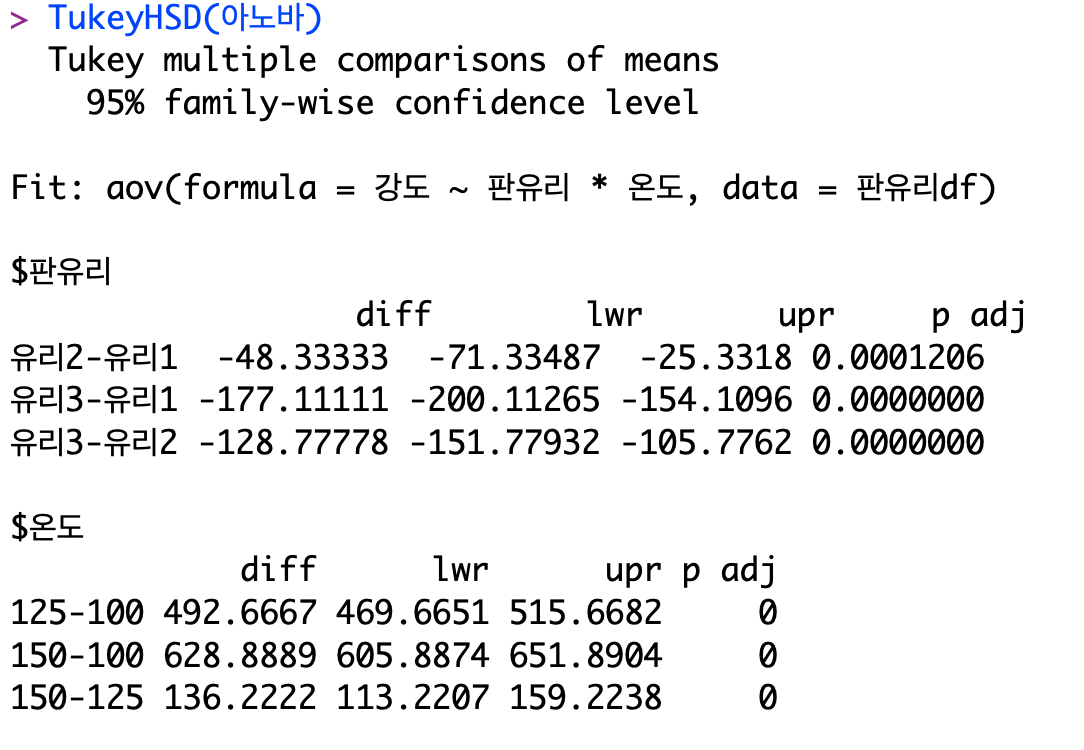
[R]
통계에 있어서 R은 파이썬보다 사용법이 훨씬 간단하다.
TukeyHSD(위에서 만든 아노바테이블모델의 변수명) 으로 모든 코드가 끝난다.
[파이썬과 R의 TukeyHSD 사후분석 결과 비교]
파이썬과 R 모두 동일한 값을 갖는 것을 확인하였다.
- 판유리, 온도 수준들의 각각의 경우의 수들이 모두 주효과가 있는 것으로 보인다. (p < 0.05)
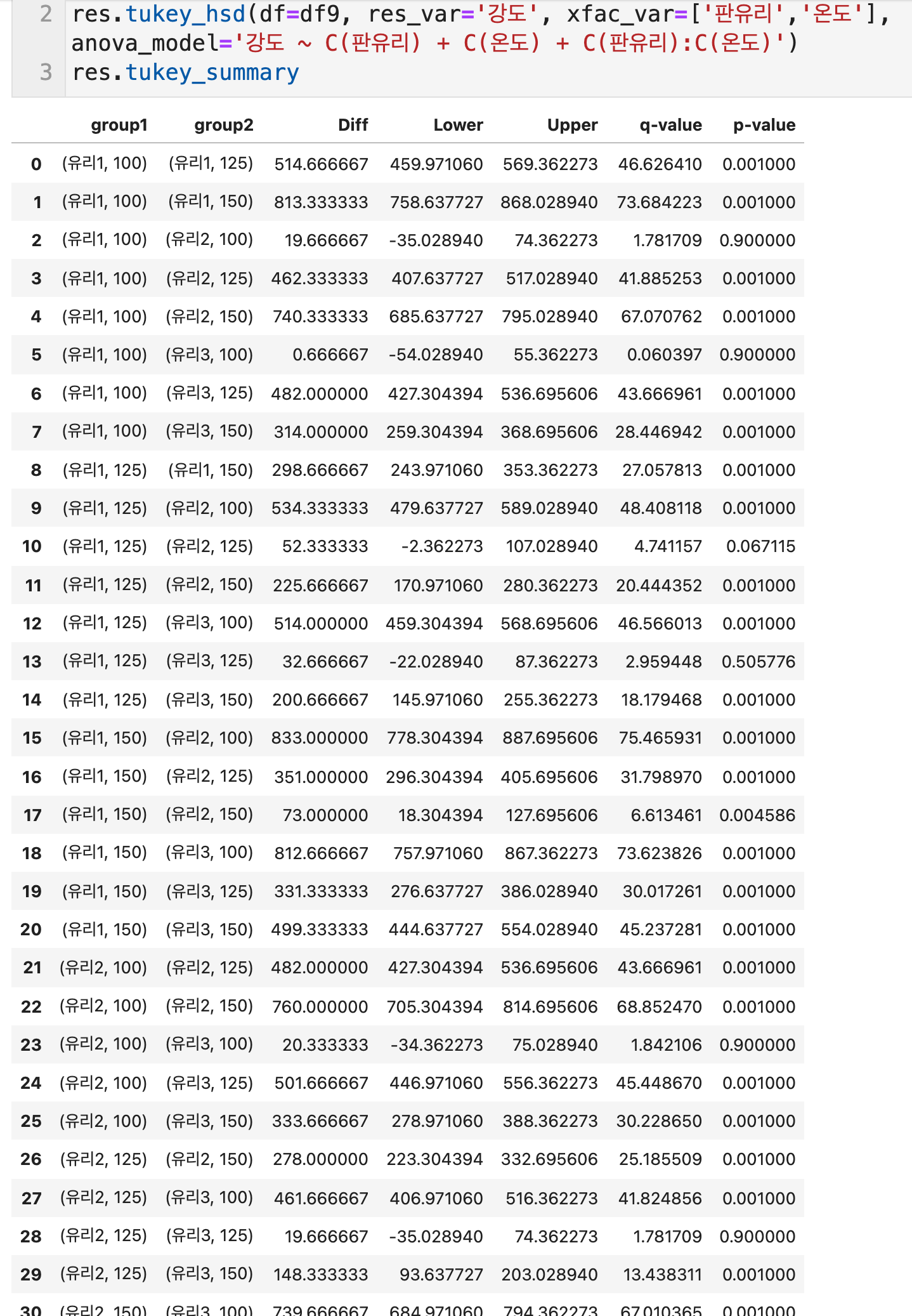
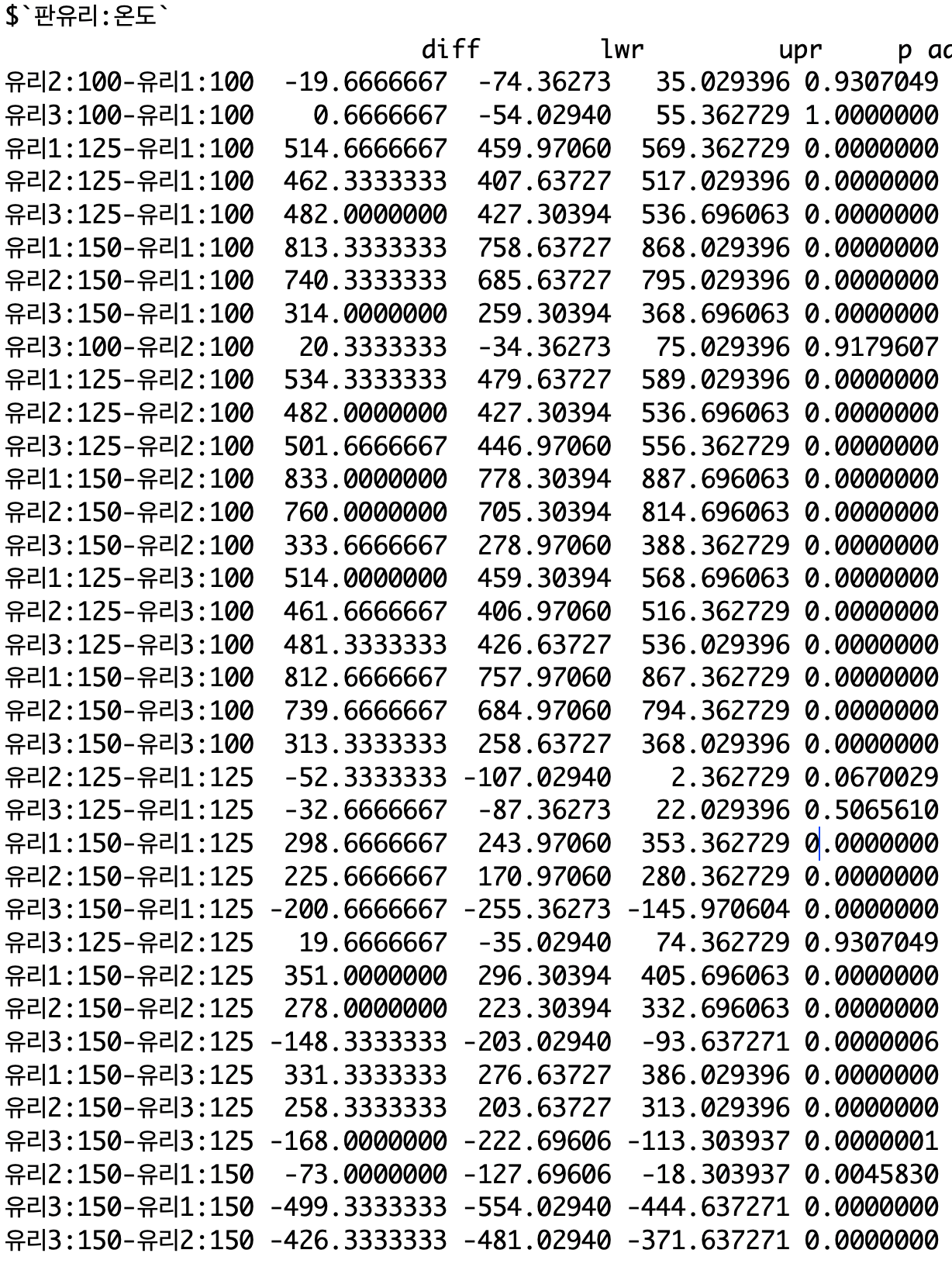
- 판유리:온도의 교호작용이 있는 경우가 많이 보인다. (p < 0.05)
- 관련 포스팅: https://lovelydiary.tistory.com/349
파이썬-R) 일원분산분석 R과 파이썬 비교 (anova table, Tukey HSD 사후분석)
#1. 파이썬으로 일원분산분석 진행 - 데이터 준비: from pandas import DataFrame DataFrame으로 데이터 만든 후, 독립변수 열을 category로 데이터 타입 변경하기 - 아노바 테이블 만들기: from statsmodels..
lovelydiary.tistory.com
'Python notes > Statistical Analysis' 카테고리의 다른 글
| 파이썬) 범주형 변수의 상관관계 확인을 위한 교차분석 하기 (+카이제곱 검정) (0) | 2021.07.22 |
|---|---|
| 파이썬) 혼동행렬 그리고 정확도, 정밀도, 민감도, f1 score 등 계산하기 (+heatmap, confusion_matrix, classification_report) (0) | 2021.07.18 |
| 파이썬) 아노바 테이블에서 자유도 계산하는 방법 (+일원분산분석, 이원분산분석의 경우) (0) | 2021.06.24 |
| 파이썬-R) 일원분산분석 R과 파이썬 비교 (anova table, Tukey HSD 사후분석) (0) | 2021.06.24 |
| 파이썬) 단순선형회귀 분석 결과 해석하기 (+statsmodel OLS Regression Results) (0) | 2021.06.23 |




댓글