ADP 기출문제 풀이) 구매 데이터 군집분석 문제 w/Python
이번 포스팅에서는 지난 26회 ADP 실기에서 출제되었던 문제를 풀어본다. 실제로 내가 합격했던 회차라서 반가운 문제이기도 하다. 이 때 해당 문제로 50점 만점에 41점을 맞았었다. 분명 9점이 날아간 이유가 있을 것이고, 부족한 풀이이지만 아래와 같이 기억을 되살려 풀이를 포스팅해 본다.
9. 구매 데이터 군집분석 문제 (ADP 실기 26회)
nvoiceNo: Invoice number. Nominal, a 6-digit integral number uniquely assigned to each transaction. If this code starts with letter ‘c’, it indicates a cancellation.
StockCode: Product (item) code. Nominal, a 5-digit integral number uniquely assigned to each distinct product.
Description: Product (item) name. Nominal.
Quantity: The quantities of each product (item) per transaction. Numeric.
InvoiceDate: Invice Date and time. Numeric, the day and time when each transaction was generated.UnitPrice: Unit price. Numeric, Product price per unit in sterling.
CustomerID: Customer number. Nominal, a 5-digit integral number uniquely assigned to each customer.
Country: Country name. Nominal, the name of the country where each customer resides.
[출처] https://www.datamanim.com/dataset/ADPpb/00/26.html

# 9-1. 결측치를 확인하고, 결측치 제거할 것
결측치를 확인한 결과, Quantity에서 25개, UnitPrice에서 97개의 결측치가 확인되었다. 전체 데이터 35801개 대비 결측치의 개수가 미비하여 삭제해도 무방할 것으로 판단한다.

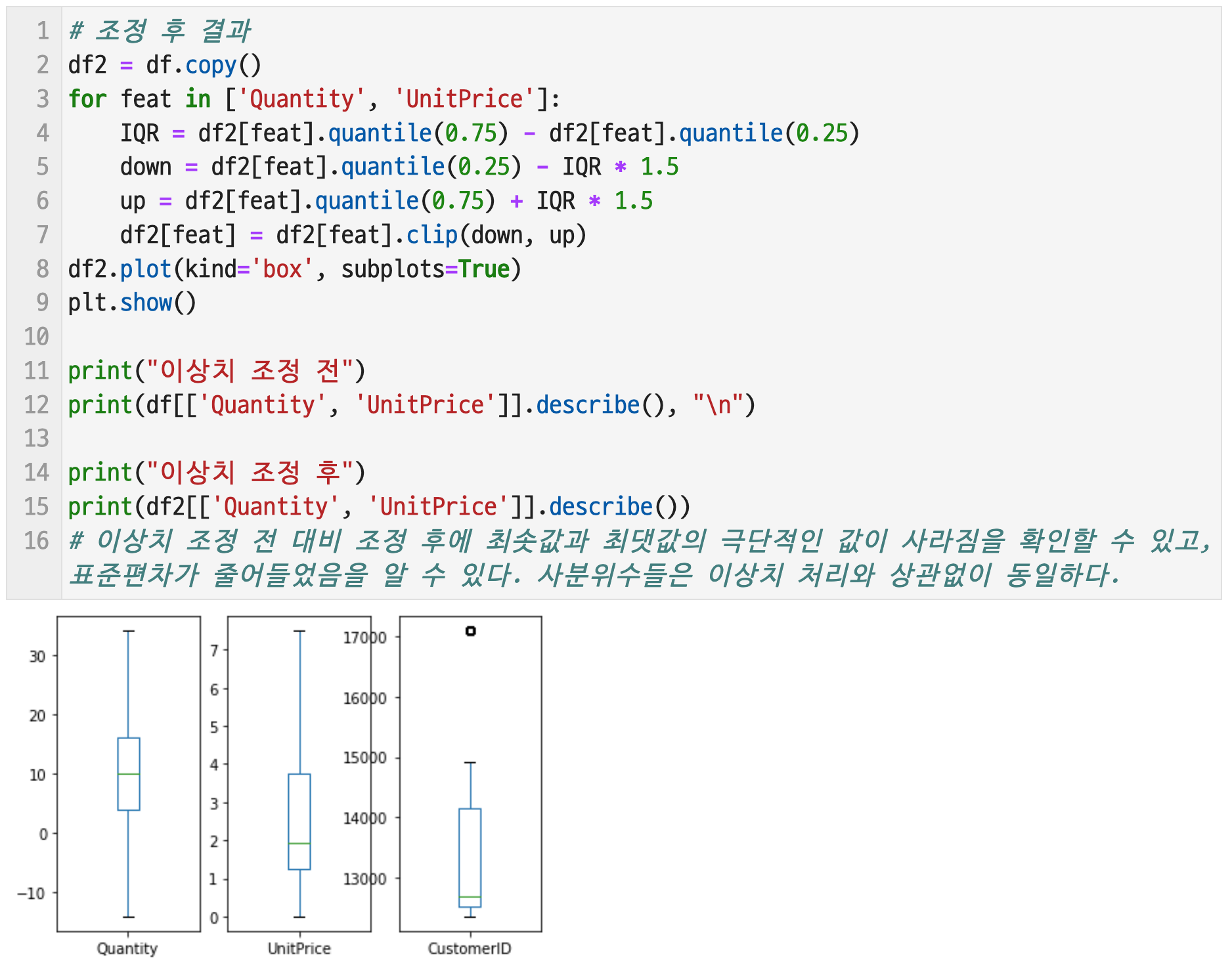
# 9-2. 이상치 제거하는 방법을 설명하고, 이상치 제거하고 난 결과를 통계적으로 나타낼 것
이상치를 제거하는 방법으로는 이상치 경계값을 벗어나는 값들을 절단하는 방법, 이상치 경계값으로 조정하는 방법 등이 있다. 이상치 제거는 수치형 변수에 대해서 실행할 수 있는데 CustomerID는 수치형 변수가 아닌 범주형 변수로 보는 것이 해석이 타당하므로, Quantity와 UnitPrice에 대해서 이상치를 확인하고 경계값으로 조정하기로 한다.

이상치 조정 전 대비 조정 후에 최솟값과 최댓값의 극단적인 값이 사라짐을 확인할 수 있고, 표준편차가 줄어들었음을 알 수 있다. 사분위수들은 이상치 처리와 상관없이 동일하다.

# 9-3. 전처리한 데이터로 군집분석 방법들 중 택2 하여 군집을 생성할 것, 군집을 생성한 과정을 각각 설명할 것
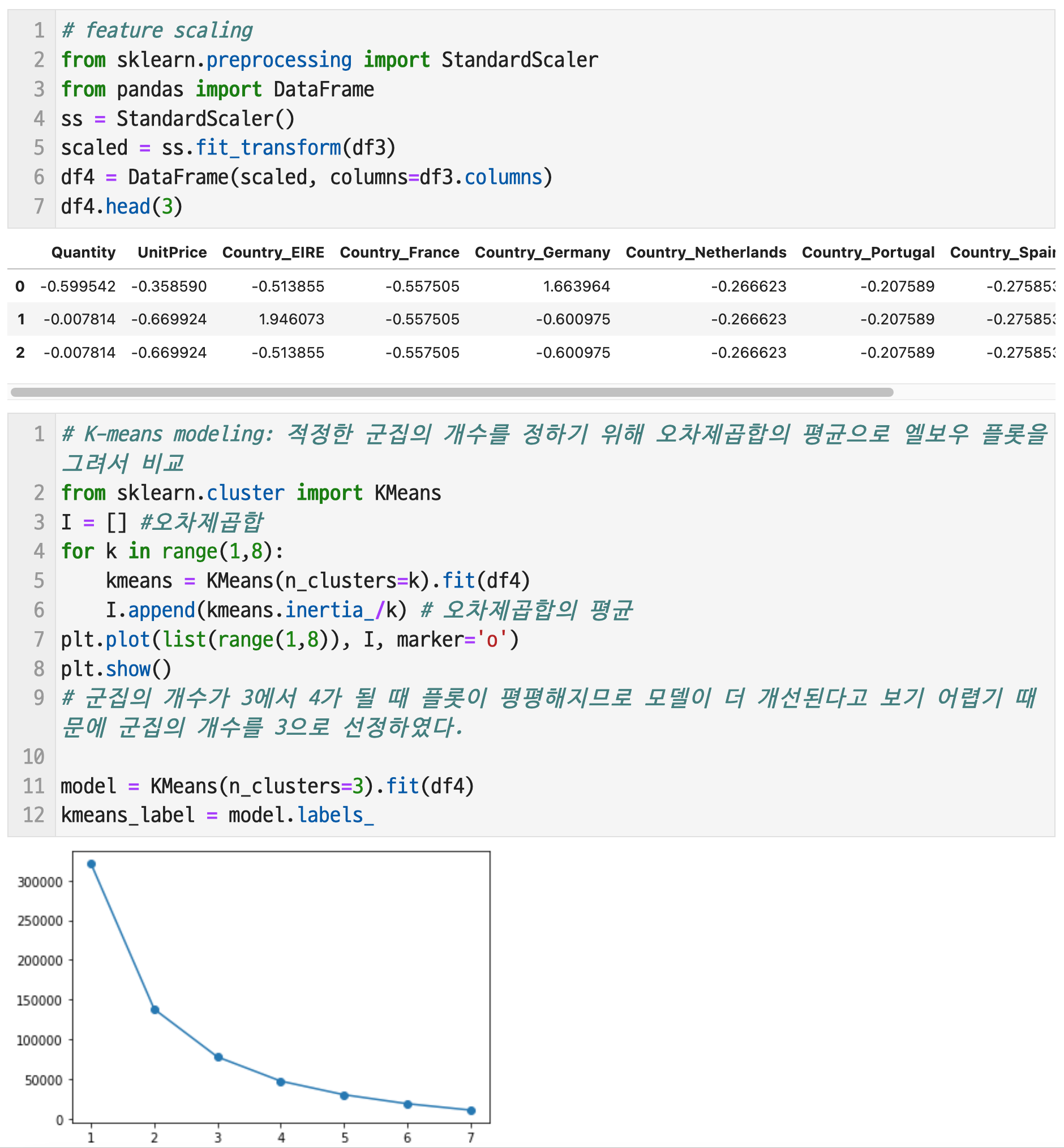
K-means와 DB-SCAN으로 군집을 생성하고자 한다. 군집 생성은 수치형 변수를 통해서 가능하기 때문에 범주형 변수의 경우 더미코딩해야 한다. 범주형 변수들 중에서 범주의 개수가 10개 이하인 Country만 전처리하고, 거리 기반 모델이기 때문에 변수들의 척도 차이를 제거하기 위해 스케일링을 진행하여 군집을 생성하기로 한다. 또한, 척도의 차이로 인한 결과의 왜곡을 피하기 위해 표준화방법으로 feature scaling도 진행하였다.
K-means modeling으로 적정한 군집의 개수를 정하기 위해 오차제곱합의 평균으로 엘보우 플롯을 그려서 비교하였다. 군집의 개수가 3에서 4가 될 때 플롯이 평평해지므로 모델이 더 개선된다고 보기 어렵기 때문에 군집의 개수를 3으로 선정하였다.
DB-SCAN modeling으로 적정한 군집의 개수를 정하기 위해 eps 후보군들의 군집 결과를 시각화 하고, 실루엣 계수로 결과를 비교하였다. 실루엣 스코어 상의 성능과 실용적인 군집의 개수를 생각했을 때 4로 선택하기로 한다.


# 9-4. 둘 중에 한 모델을 선택하고, 그 이유를 설명할 것
실루엣 스코어 성능 면에서 군집이 더 잘 이루어졌다고 판단되는 DB-SCAN을 선택하기로 한다.

# 9-5. 선택한 모델을 기반으로 생성한 군집들의 특성을 분석할 것
이상치DB-SCAN을 기반으로 생성한 군집 정보를 원본 데이터에 입력하여 군집들의 특성을 확인한다. 0~3의 4개 군집으로 된 것을 알 수 있으며, cluster0이 83%로 절대 다수를 차지하고, cluster2가 4%로 가장 작은 비율임을 알 수 있다.

cluster0: 전체 구매 데이터의 83%를 차지하는 cluster0은 평균 10.98개의 상품을 구매하며, 평균 가격대는 2.81달러의 제품을 구매하는데 그 범위는 0~7.5달러인 것으로 나타났다. CustomerID에 의하면 240명의 customer가 구매하는 것으로 나타났고, 가장 많은 구매를 한 customer는 5875건을 구매하였다. InvoiceNo에 따르면 총 1602건의 구매영수증이 생성되었고, POST라는 StockCode의 제품이 851건으로 가장 많이 판매되었다. 국가 별로는 Germany Customer가 가장 많은 빈도(9467)를 차지하였다.

cluster1: 전체 구매 데이터의 6.6%를 차지하는 cluster1은 평균 26.12개의 상품을 구매하며, 평균 가격대는 2.18달러의 제품을 구매하는데 그 범위는 0~7.5달러인 것으로 나타났다. CustomerID에 의하면 9명의 customer가 해당하고, 가장 많은 구매를 한 customer는 2082건을 구매하였다. InvoiceNo에 따르면 총 101건의 구매영수증이 생성되었고, POST라는 StockCode의 제품이 39건으로 가장 많이 판매되었다. 국가 별로는 Netherlands Customer로 구성되어 있다.

cluster2: 전체 구매 데이터의 4.1%를 차지하는 cluster2는 평균 10.1개의 상품을 구매하며, 평균 가격대는 2.5달러의 제품을 구매하는데 그 범위는 0.12~7.5달러인 것으로 나타났다. CustomerID에 의하면 19명의 customer가 해당하고, 가장 많은 구매를 한 customer는 376건을 구매하였다. InvoiceNo에 따르면 총 70건의 구매영수증이 생성되었고, POST라는 StockCode의 제품이 30건으로 가장 많이 판매되었다. 국가 별로는 Portugal Customer로 구성되어 있다.

cluster3: 전체 구매 데이터의 5.2%를 차지하는 cluster3은 평균 13.41개의 상품을 구매하며, 평균 가격대는 2.71달러의 제품을 구매하는데 그 범위는 0.~7.5달러인 것으로 나타났다. CustomerID에 의하면 21명의 customer가 해당하고, 가장 많은 구매를 한 customer는 355건을 구매하였다. InvoiceNo에 따르면 총 71건의 구매영수증이 생성되었고, POST라는 StockCode의 제품이 33건으로 가장 많이 판매되었다. 국가 별로는 Switzerland Customer로 구성되어 있다.

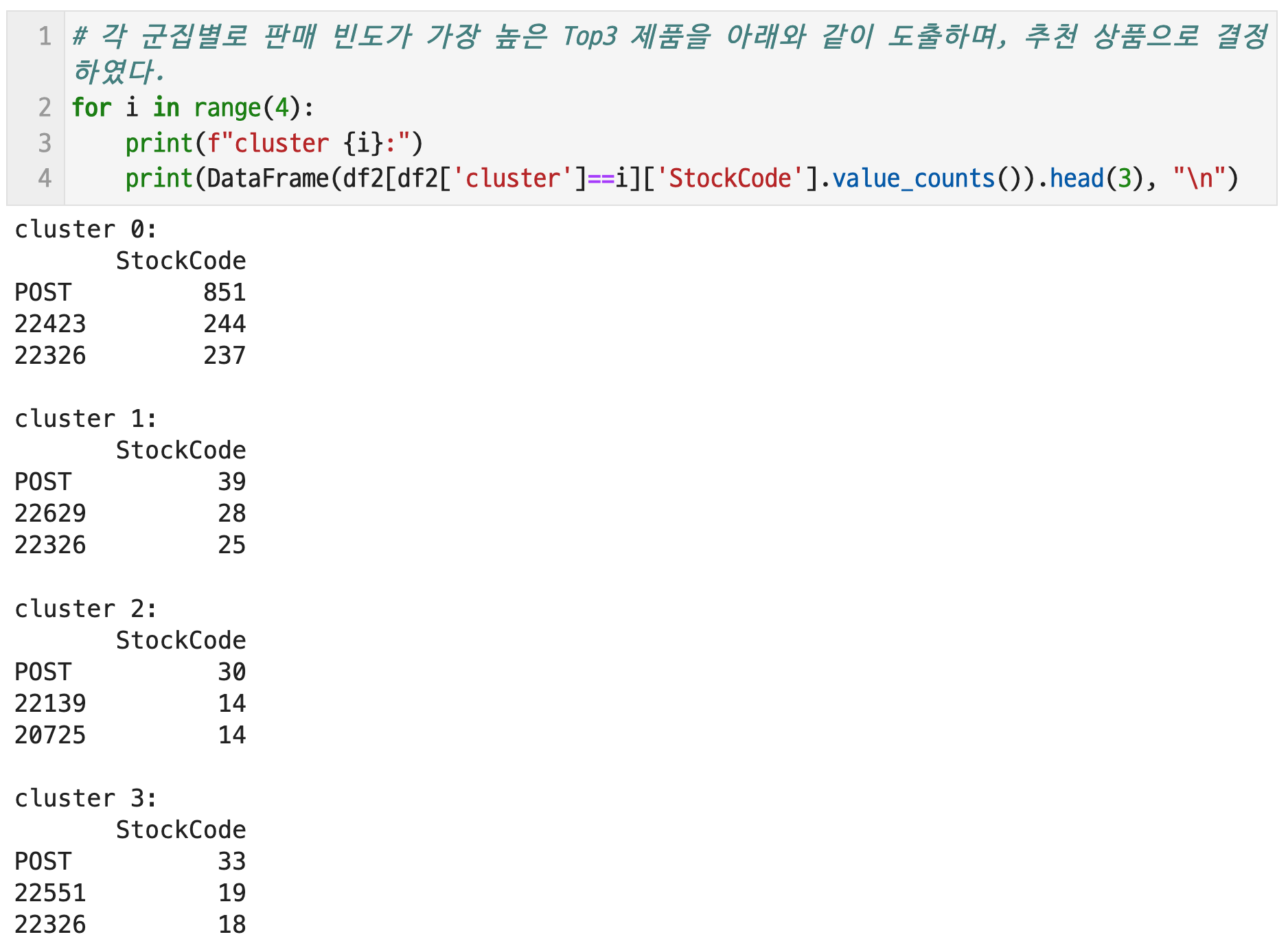
# 9-6. 각 군집 별 대표 추천 상품을 도출할 것
각 군집별로 판매 빈도가 가장 높은 Top3 제품을 아래와 같이 도출하며, 추천 상품으로 결정하였다.
# 9-7. CustomerID가 12413인 고객을 대상으로 상품을 추천할 것
아래와 같이 CustomerID가 12413인 고객은 cluster0에 해당되는 고객이다. 이 고객에는 StockCode가 POST, 22423, 22326인 제품들을 추천하면 구매할 확률이 높다고 볼 수 있다.
