ADP) 3-3. 파이썬으로 리샘플링, 데이터분할 - 부트스트랩, 일반적 데이터 분할(훈련/테스트), 홀드아웃방법, K-fold 교차분석
파이썬 데이터 리샘플링, 분할 방법들
부트스트랩
모집단에서 추출한 표본에 대해서 또 다시 재표본을 여러번 추출하여 모델을 평가하거나 데이터의 분포를 파악하는 재표본 추출방법이다. 샘플링을 할 때는 단순랜덤 복원 추출법을 사용하여 동일한 크기의 표본을 여러개 생성하므로, 특정 데이터가 여러 샘플에 포함될 수도 있고 혹은 어떠한 샘플에도 포함되지 않을수도 있다.
부트스트랩을 통해 100개의 샘플을 추출했을 때 샘플에 한번도 선택되지 않는 원데이터가 발생할 확률은 36.8%이다. 이러한 데이터를 OOB(out of bag)데이터라고 하며, OOB 데이터의 실제값과 예측값 사이의 오차로 정의되는 값을 OOB-error라고 한다.
ensenble 기법들(Bagging, Boosting)에서 파라미터로 Bootstrap=True/False 적용하여, 재표본 추출할지 여부를 정할 수 있다.
단순랜덤복원추출법으로 동일한 크기의 여러 표본을 생성하려면, 지난번 포스팅한 단순랜덤 추출법을 참고하면 된다.
https://lovelydiary.tistory.com/410
ADP) 3-2. 파이썬으로 표본 추출: 단순랜덤 추출법, 계통추출법, 집락추출법, 층화추출법
파이썬으로 표본 추출 (Sampling) 하기 단순랜덤추출법 (simple random sampling) 각 샘플에 번호를 부여하여 임의의 n개를 추출하는 방법으로 각 샘플은 선택될 확률이 동일하다. 추출한 element를 다시
lovelydiary.tistory.com
일반적인 데이터 분할 및 홀드아웃방법
일반적으로 데이터 분할은 train data(70%), test data(30%)로 비율에 따라 랜덤으로 데이터를 분할한다.
여기서 홀드아웃방법(Hold-out: 데이터를 랜덤하게 두 분류로 분리하여 교차 검정을 실시, 하나는 훈련용 데이터, 하나는 검증용 데이터로 사용 데이터를 랜덤하게 두 분류로 분리하여 교차 검정을 실시)은 train data(50%), test data(50%)로 데이터를 분할해서 교차검정을 실시하면 된다.
파이썬으로 데이터 분할을 구현하기 위해서는 데이터 셋을 설명변수(X)와 타겟변수(y)로 나눈 후, Scikit Learn의 train_test_split 함수를 사용하면 구할 수 있다. 홀드아웃의 경우 test_size 파라미터를 0.5로 지정하면 된다.

K-fold 교차분석 (k-fold cross validation)
데이터를 k개의 집단으로 나눈 뒤 k-1개의 집단으로 분류기를 학습시키고, 나머지 1개의 집단으로 분류기의 성능을 테스트하는 방법이다. 이 과정을 k번 반복하여 모든 데이터가 학습과 검증에 사용될 수 있도록 하고, 최종적으로 k번의 테스트를 통해 얻은 MSE(평균제곱오차)값들의 평균을 해당 모델의 MSE값으로 사용한다.
train set과 test set의 비율은 fold를 몇번으로 하느냐에 따라 달라진다. fold를 5로 가져가면, train set 4/5, test set 1/5의 비율이 되고, fold를 10으로 가져가면, train set 9/10, test set 1/10의 비율이 된다.
K-fold 교차분석은 Scikit Learn의 KFold 함수로 구현할 수 있다. 이 함수는 train과 test set으로 나뉘어진 인덱스만 반환한다. 그래서 이 반환된 인덱스를 원래의 데이터셋에 적용해서 그 인덱스에 해당하는 데이터값들을 받아와야 한다. KFold의 파라미터 n_splits는 fold의 횟수를 나타내고, shuffle은 데이터 분할 전에 데이터를 섞을지 여부를 나타낸다.
아래는 n_splits를 4로 했기 때문에 train set과 test set의 비율이 각각 0.75(=3/4), 0.25(=1/4)로 나타났다.

층화 K-fold 교차분석 (Stratified k-fold cross validation)
타겟 변수값이 랜덤으로 여러번 fold하는 과정에서 어떤 분할 데이터셋에서는 타겟 변수의 level 중 일부가 누락되거나 level의 비율이 현저히 다를 수 있다. 이것을 방지하기 위해, 모든 분할 데이터셋의 타겟 변수 level의 비율이 원본과 동일한 비율로 나누어지도록 하는 k-fold 교차분석 방법이다.
Scikit Learn의 StratifiedKFold 함수로 구현할 수 있으며, 이 역시 train과 test set의 인덱스를 반환해 준다. 아래는 반복문으로 데이터셋을 분할하고 있는데 실제로 모델을 fitting하는 식을 그 아래에 넣고, 모델링 결과를 모으는 코드를 그 아래에 넣을 수 있다.
아래 결과를 보면, 원본 타겟변수의 level 비율과 타겟변수 y의 훈련세트의 level 비율과 y의 test세트의 level 비율이 동일한 것을 확인 할 수 있다. 그와 동시에 train - test set의 비율은 k-fold에 따른 비율을 맞춘다.


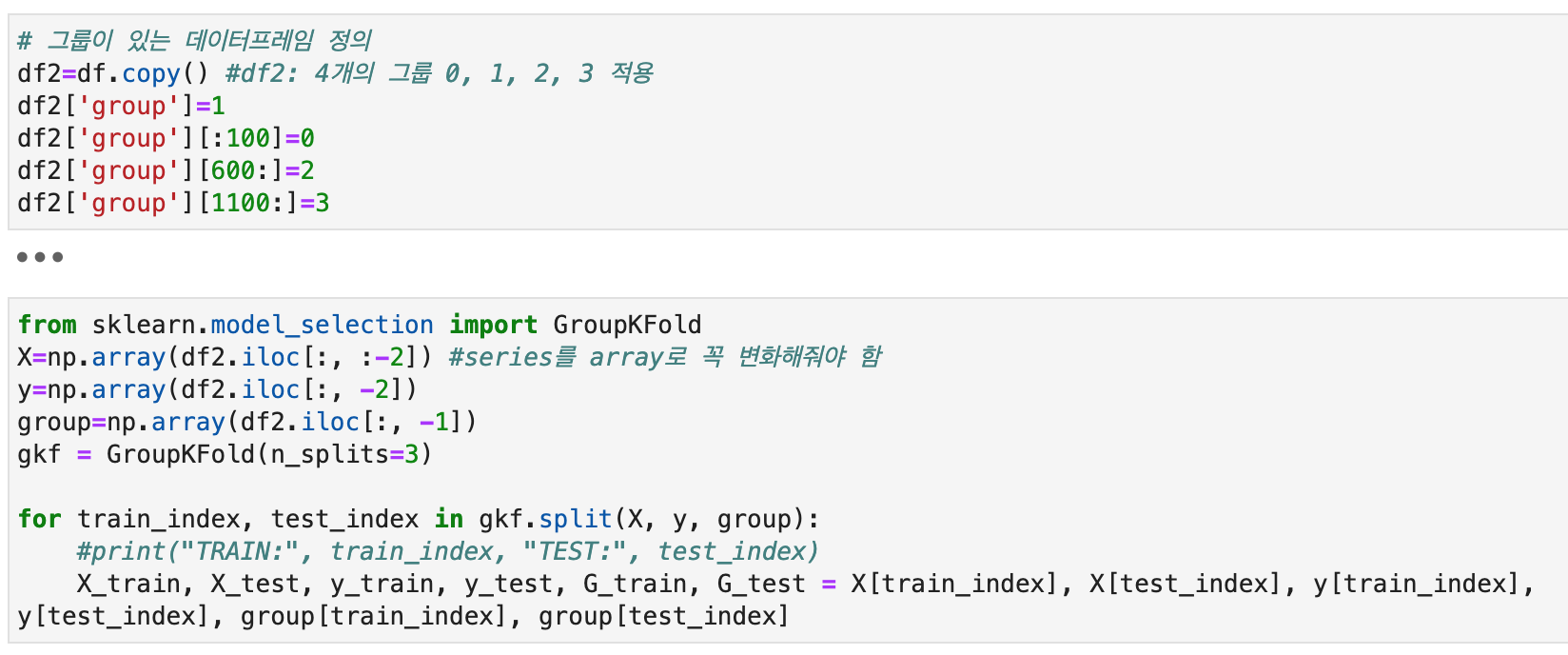
Group K-fold 교차분석
매 데이터 분할 시마다 각 group의 데이터들 중 한 그룹의 데이터를 test 데이터로 적용하고 이를 돌아가면서 사용하여 k-fold를 진행한다. 이때문에 group의 개수는 fold의 개수와 같거나 fold 개수보다 커야 한다. group의 개수와 fold의 개수가 같을 경우, 모든 group들이 한번씩 test 데이터로 적용될 것이고, group의 개수보다 fold의 개수가 적을 경우 일부 group들은 test 데이터로 적용이 되지 않고 교차 분석이 완료될 것이다.


Stratified Group K-fold 교차분석
Group K-fold 방식인데 training 및 test 타겟변수의 class가 원본 데이터의 class 비율과 동일하게 가져가도록 데이터를 분할하는 방법이다. 구현 방법은 위의 GroupKFold 함수 대신 StratifiedGroupKFold 함수를 사용하면 된다.
Scikit Learn에 있는 5개의 데이터 분할 방법을 다 해서 비교를 해보았는데 데이터 상황에 따라 적절한 교차 분석법을 선택해서 사용하면 되겠다.
윤종식, ADP 데이터 분석 전문가 (부산: (주)데이터에듀, 2021)
윤종식, ADsP 데이터 분석 준전문가 (부산: (주)데이터에듀, 2021)
Model Selection, Scikit Learn, https://scikit-learn.org/stable/modules/classes.html#module-sklearn.model_selection