ADP) 3-2. 파이썬으로 표본 추출: 단순랜덤 추출법, 계통추출법, 집락추출법, 층화추출법
파이썬으로 표본 추출 (Sampling) 하기
단순랜덤추출법 (simple random sampling)
각 샘플에 번호를 부여하여 임의의 n개를 추출하는 방법으로 각 샘플은 선택될 확률이 동일하다. 추출한 element를 다시 집어 넣어 추출하면 복원 추출, 다시 집어넣지 않고 추출하면 비복원 추출이다.
pandas의 DataFrame으로 만든 데이터프레임 객체인 df에 .sample() 함수를 써서 전체 데이터 중 일부 샘플을 랜덤으로 추출할 수 있다. df.sample(n=2, replace=False)의 식으로 사용하는데, n은 추출할 샘플의 개수이고 replace는 샘플을 복원해서 뽑을지 여부이다. replace=False로 파라미터를 설정하면, 샘플을 뽑을 때마다 뽑은 샘플을 복원하지 않고 연속적으로 샘플을 뽑는다.

df.sample(frac=0.1)처럼 frac 파라미터를 써서 전체 데이터의 몇퍼센트를 랜덤으로 추출할 것인지 설정할 수도 있다.

또한 샘플링을 할 때 파라미터 weights에 특정 열의 값을 입력하면, 해당 열의 값이 크면 클수록 표본으로 뽑힐 확률이 높도록 가중치를 설정할 수 있다. n과 frac은 둘 중 하나를 선택해서 파라미터로 입력해야 하지만 weights는 두 경우 다 적용 가능하다.
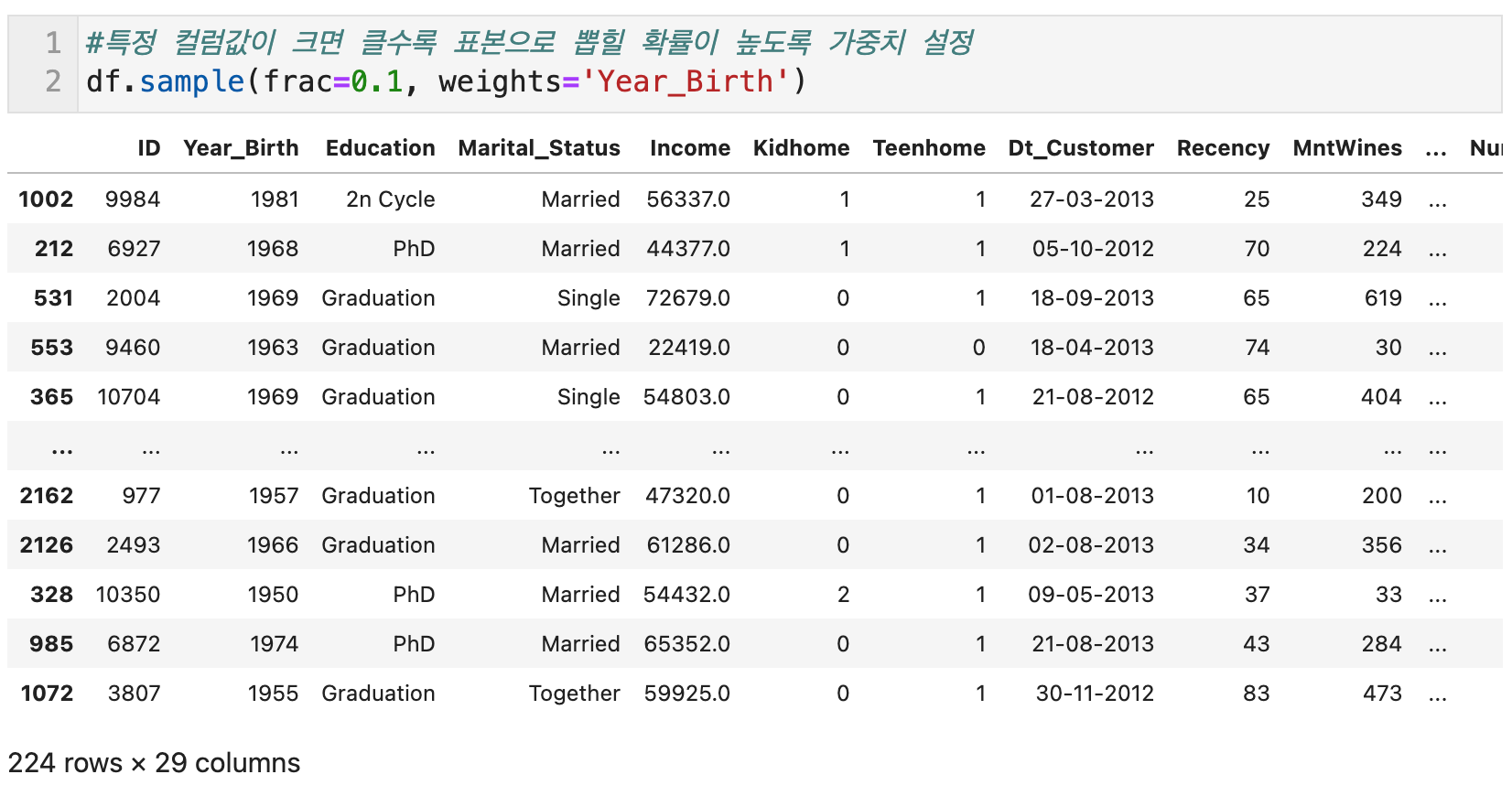
일반적으로 한 행이 하나의 데이터 포인트라고 볼 수 있기 때문에 행 방향으로(axis=0) 데이터를 랜덤하게 추출한다. 하지만 필요 시 열 방향(axis=1)으로도 데이터를 랜덤하게 추출할 수 있다. 그러면 여러가지 열들 중에서 n개의 열들이 랜덤으로 추출된다.

계통추출법 (systematic sampling)
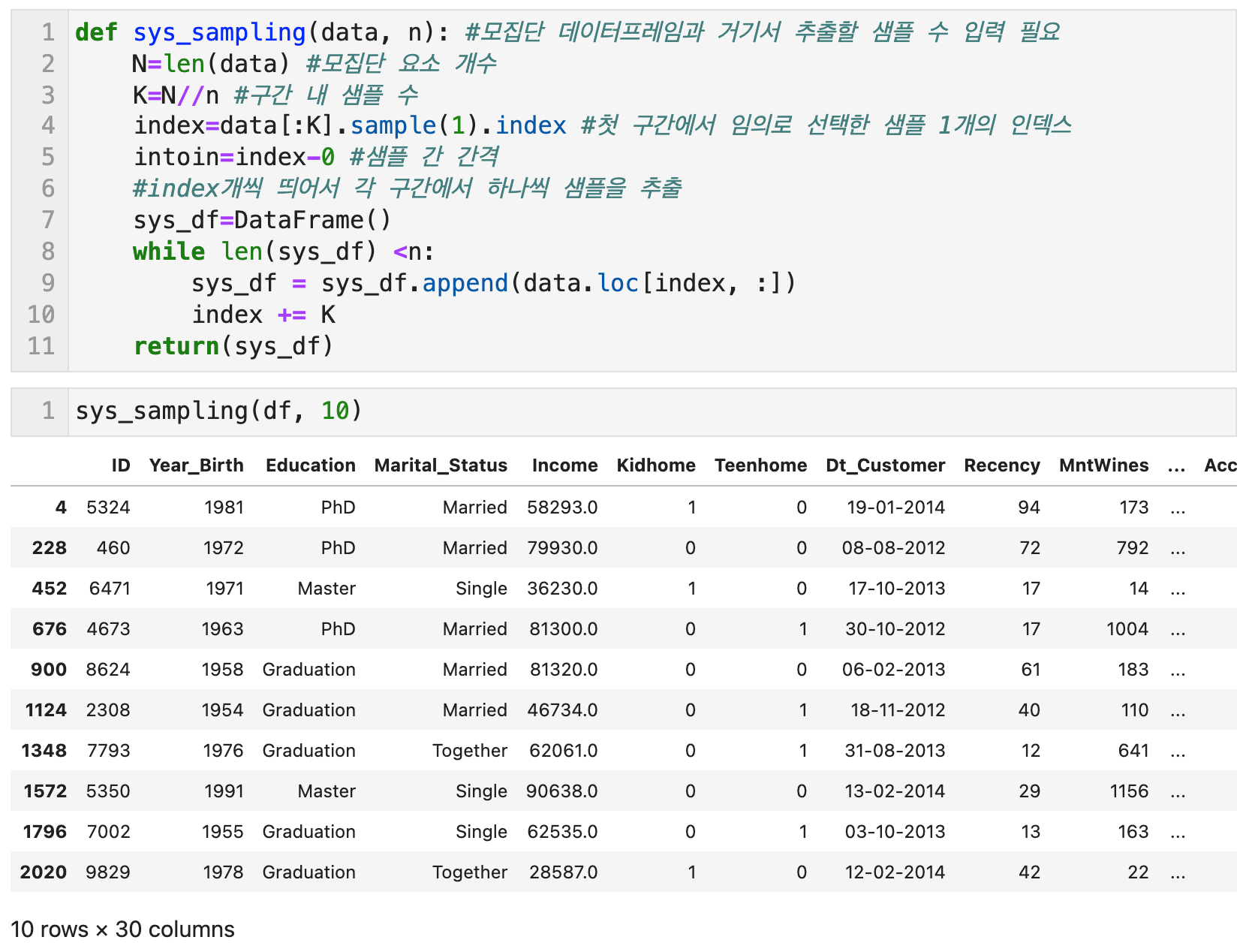
단순램덤추출법의 변형된 방식으로서 일단, 번호를 부여한 샘플을 나열한다. 총 N(30)개의 모집단에서 n(5)개의 샘플을 추출하기 위해서 N/n으로 구간을 나눈다. 이 경우 각 구간에 들어있는 샘플의 수는 K(6)가 된다. K(6)개의 샘플이 들어 있는 첫 구간에서 임의로 샘플을 하나 선택하고, K(6)개씩 띄어서 각 구간에서 하나씩 샘플을 추출하는 방법이다.
단순한 알고리즘이라 그런지 별도의 함수가 없어서, 함수를 정의해서 사용하였다.
층화추출법 (stratified random sampling)
이질적인 원소들로 구성된 모집단에서 각 계층을 고루 대표할 수 있도록 표본을 추출하는 방법이다. 유사한 원소끼리 몇개의 층(stratum)으로 나누어 각 층에서 랜덤 추출하는 방법이다. 비례층화추출법과 불비례층화추출법이 있다. 층 내 요소들은 유사하지만, 층과 층의 요소들은 상이하다.
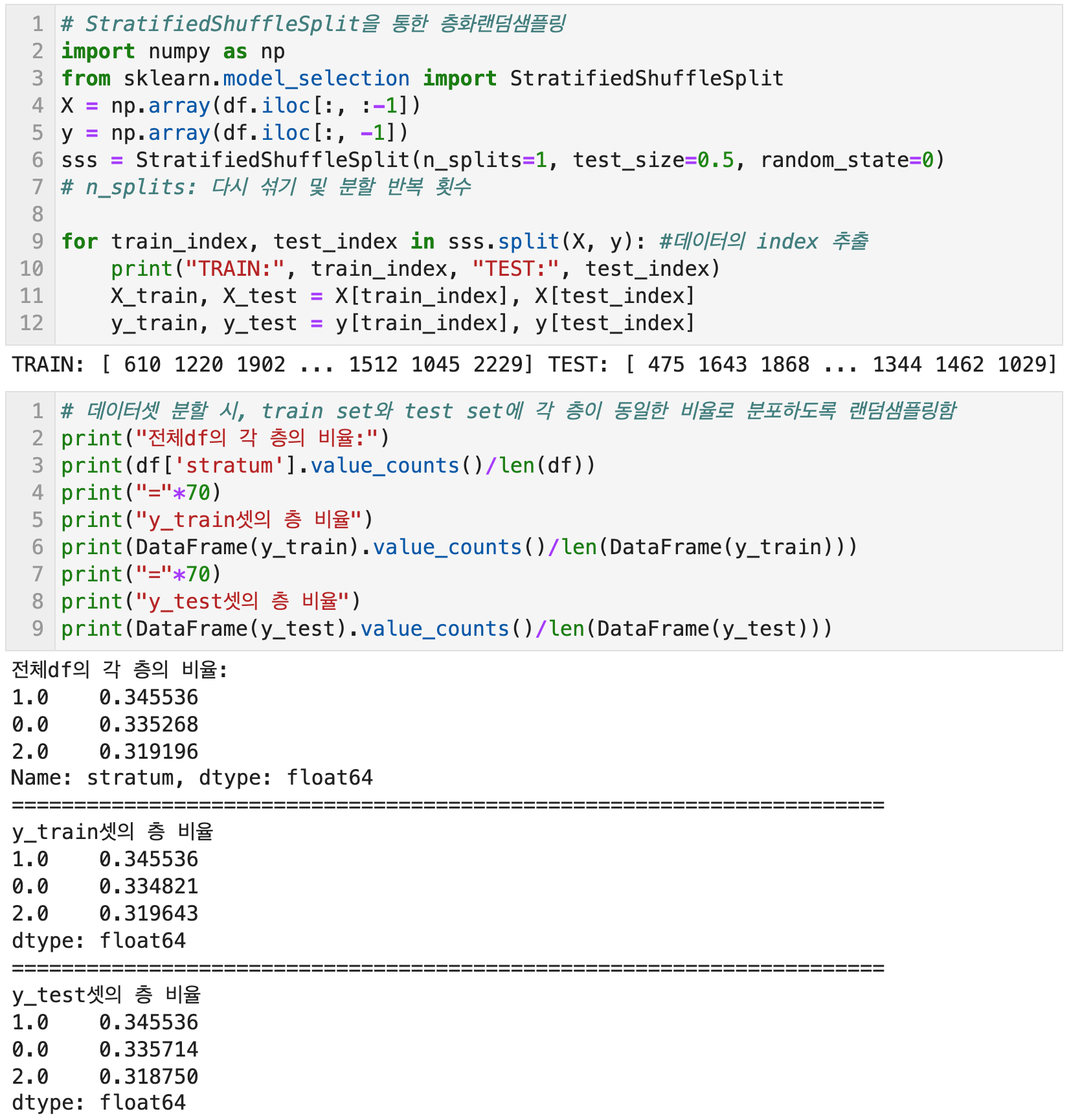
Scikit Learn의 StratifiedShuffleSplit - 각 층의 비율을 고려해 무작위로 train/test set을 분할하는 인덱스를 반환한다. 비례층화추출법에 해당한다.
여기서 파라미터들을 살펴보면 n_splits는 데이터를 섞는(shuffling) 횟수이다. test_size는 train set와 test set의 분할 비율을 의미한다. 파라미터를 test_size로 해도 되고 train_size로 해도 되는데 둘 중 하나만 적으면 된다.
원본 데이터셋의 각 층의 비율과, 층화추출법을 통해 샘플링 된 후 분할된 train/test set의 데이터 층의 비율이 동일한 것을 확인할 수 있다.
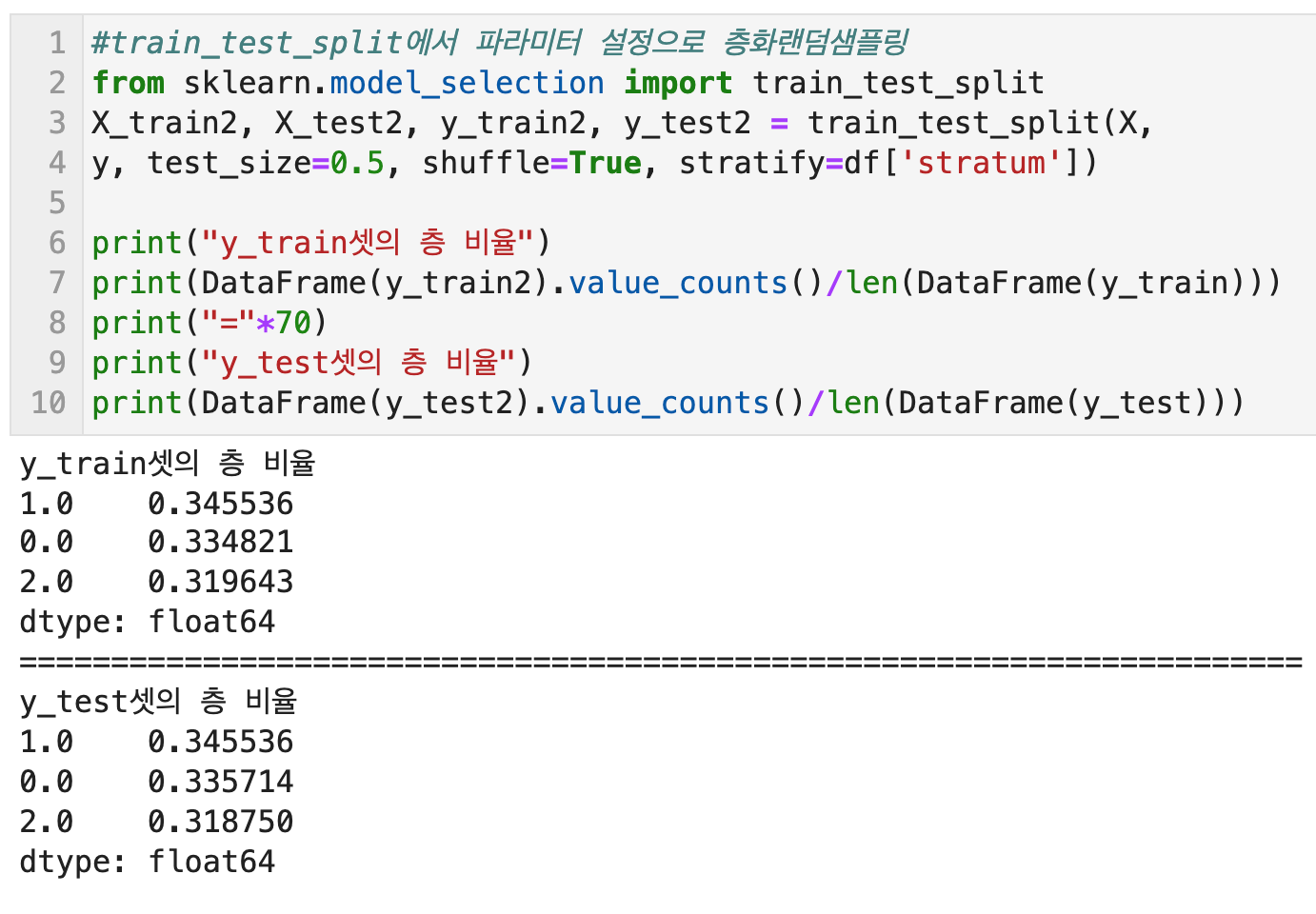
파이썬으로 층화추출하여 train/test set을 나누는 또 다른 방법은 Scikit Learn의 train_test_split 함수를 사용하는 방법이다. 위의 함수보다 더 간단하다. 파라미터에 shuffle=True를 넣고, stratify="층 데이터"를 넣으면 된다.
집락추출법 (cluster random sampling)
군집을 구분하고 군집별로 단순랜덤 추출법을 수행한 후, 모든 자료를 활용하거나 샘플링하는 방법이다. 지역표본추출과 다단계표본추출이 이에 해당한다. 이 경우, 군집 내 요소들은 상이하지만, 군집과 군집은 비교적 유사한 특성을 띈다.
위의 층화추출법에서 사용한 함수들을 사용해서 층 대신 집락 데이터를 적용하면 된다.
윤종식, ADP 데이터 분석 전문가 (부산: (주)데이터에듀, 2021)
윤종식, ADsP 데이터 분석 준전문가 (부산: (주)데이터에듀, 2021)
StratifiedShuffleSplit, Scikit Learn, https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedShuffleSplit.html#sklearn.model_selection.StratifiedShuffleSplit